Structuring Your Teams for Software Reliability

How well positioned is your team to ship reliable software? What are the different roles in engineering that impact reliability, and how do you optimize the ratio of software engineers to SREs to DevOps within teams? These questions can be hard to answer in a quantifiable way, but projecting different scenarios using systems thinking can help. Will Larson’s blog post Modeling Reliability does just that, and serves as inspiration for this article. In this article, we will abstract away the mathematical formulas for a broader audience to intuitively understand team construction for reliability.
Systems thinking is a methodology for analyzing complex ideas. It allows us to zoom out to a higher level and examine the interactions between components within the system. This can help us simplify the complexity and see the bigger picture. The best way to explain what we mean is through an example, so let’s dive right in.
Reliability in the simplest possible system
First, we need to define a goal for our system. The goal we set for our reliability system is maintaining stability in functionality while we continue to ship new features. Your company may have a different definition, and that would impact your system model.
In order to tell how stable our functionality is, we need to measure how many occurrences of instability there are -- in other words, the number of incidents. As we continuously ship new features, some will unfortunately result in incidents due to unforeseen dependencies or vulnerabilities. When our team resolves incidents, the incident becomes mitigated.
In this example, we don’t care what or how many features there are. We just care that some defect and become incidents. Similarly, after we mitigate the incidents, the main metric we’re evaluating is the rate (speed and quantity) at which we’re mitigating them.
 Key to flow chart
Key to flow chart
This is the simplest model to really understand how we’re doing with reliability. At a minimum, if we instrument the number of active incidents, defect rate, and mitigation rate, then we can quantify and see how reliable our system is. From there we can develop a program for handling incidents to try and lower the defect rate and increase the mitigation rate to be within ranges we find acceptable.
Modeling the change rate of features and deploys
To scope our system more accurately, we also take features and deploys into consideration. The rate of new deploys isn’t constant, partly because the number of developers in a company isn’t constant. As our company grows, the quantity of developers also grows, as (hopefully) do investments in tooling and automation to improve innovation velocity. With these changes, the quantity of features increases.
 Flow chart of feedback loop
Flow chart of feedback loop
However, as new services get onboarded and operational complexity grows within a system, the volume of incidents increases at a rate that is likely much faster than the rate of hiring additional engineers who can handle them. This means you’ll reach a bottleneck where you cannot ship more features because your engineers will be spending all their time fixing ongoing problems.
In fact, this becomes a huge issue in Gene Kim’s “The Phoenix Project.” In this novel, an engineer named Brent becomes a massive bottleneck to the critical application Phoenix. Brent is often so busy with mitigation work and helping others that he has little to no time to devote to the project itself. One of the book’s most important statements is that you can only move as quickly as your bottleneck allows, and that any improvements you do to the system will be next to worthless if it doesn’t help the bottleneck. In this context, the bottleneck will likely be engineering hours. You simply won’t have enough time to spend to fix the issues and ship new features.
The two types of reliability work
So how do we prevent incidents from overwhelming the system? By adding components to our system to lower the defect rate and to increase the mitigation rate. As a company grows bigger, dedicated staff would likely be required for this effort. That’s where SREs come in.
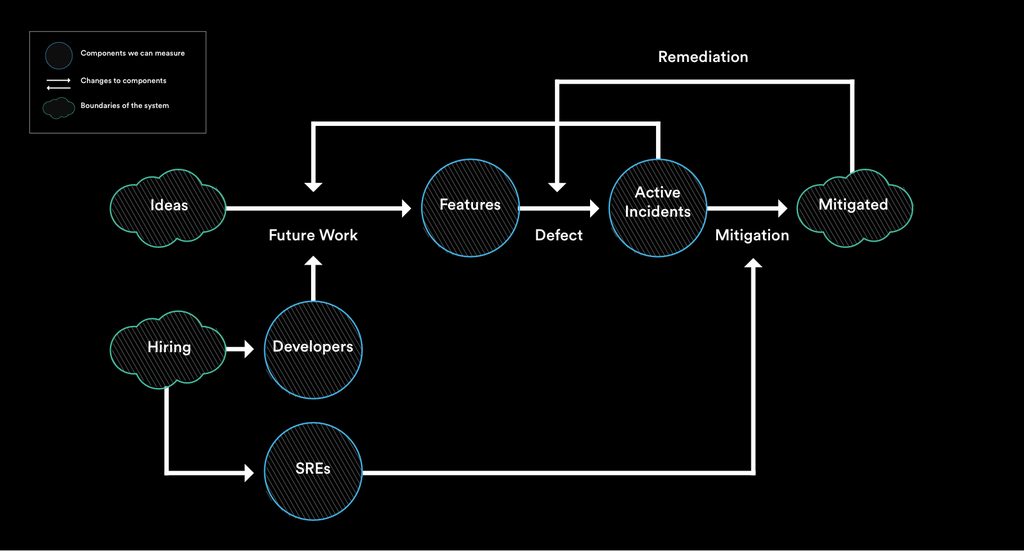 Flow chart of feedback loop with SRE added
Flow chart of feedback loop with SRE added
There are two main types of reliability work. The first is mitigation, which is a linear fix that’s often referred to as firefighting. In other words, you’re fixing problems as they come. The second is change management, which is a non-linear fix that proactively reduces the defect rates through projects like migrating to better tools and refactoring spaghetti code. While SREs support both these types of work, they should spend more time on the latter. In Google’s SRE handbook, it states that SREs should allocate approximately 50% of their time on this sort of project work for the company to really see improvements in reliability.
Long term, SREs encourage the entire engineering organization to adopt better reliability practices, thus creating a more effective team.
However, it's also important to note that if a system becomes unstable for a long period of time with no effort to improve, SREs will likely start withdrawing from the application. If developers don't make an effort to help prioritize reliability, the SRE may hand back the pager.
Because reliability is a team sport, SRE is a highly cultural endeavor, which requires buy-in across many stakeholders.
Conclusion: Kickstarting your SRE team
To balance your mix of developers and SREs properly so you can effectively lower defect rates, two things need to happen:
- You need to hire. It’s not enough to have a fixed number of SREs because as you hire more devs, even with a reduced defect rate, the number of defects will still be increasing significantly. To keep the growing number of defects under control, you need to design an SRE team that is of a defined relative size to the overall engineering organization, say one to twenty.
- Things need to get worse before they get better. In the beginning of SRE implementation, you’ll need to discuss reasonable expectations for your team. For a while, incidents will likely increase before they get better, and team members shouldn’t feel discouraged about this. An increase in incidents occurs when technical debt is being drained. When SREs begin draining technical debt, latent incidents are exposed. These incidents are like landmines; you don’t know they even exist until you step on them. Latent incidents are extremely common in legacy systems. This can be a huge pitfall for great teams. If incidents spike due to remediation efforts, it doesn’t mean that the team is failing. In fact, it’s the opposite. The team is exposing and fixing dangerous issues. By letting your team know ahead of time that things will likely be worse before they get better, you can avoid this issue and boost your system’s reliability plus your team’s morale.
With the tools above, you can start thinking about the allocation of investments across your system to optimize for reliability by adding SREs to your organization. Of course, with all system models, the exact boundaries are not clear cut, and you may want an expanded scope to capture a fuller picture. Boundaries will likely change over time and will need to be reevaluated periodically. However, we hope this framework provides some high-level ideas on how you can quantify the impacts of SRE specifically on your team.
If you liked this article, you may want to check out these others:
- The Tipping Point: 4 Signs Software Reliability Should be a Top Priority at Your Company
- How to Avoid the 5 SRE Implementation Traps that Catch Even the Best Teams
- Understanding Reliability Block Diagrams
Written by: Owen Wang and Hannah Culver
Edited by: Ancy Dow and Charlie Taylor
Get similar stories in your inbox weekly, for free
Share this story:

Blameless
Blameless is the industry's first end-to-end SRE platform, empowering teams to optimize the reliability of their systems without sacrificing innovation velocity.
Published by
Blameless is the industry's first end-to-end SRE platform, empowering teams to optimize the reliability of their systems without sacrificing innovation velocity.

Latest stories

Best Cloud Hosting in the USA
This article explores five notable cloud hosting offers in the USA in a detailed way.

Best Dedicated Hosting in the USA
In this article, we explore 5 of the best dedicated hosting providers in the USA: …


The best tools for bare metal automation that people actually use
Bare metal automation turns slow, error-prone server installs into repeatable, API-driven workflows by combining provisioning, …

HIPAA and PCI DSS Hosting for SMBs: How to Choose the Right Provider
HIPAA protects patient data; PCI DSS protects payment data. Many small and mid-sized businesses now …

The Rise of GPUOps: Where Infrastructure Meets Thermodynamics
GPUs used to be a line item. Now they're the heartbeat of modern infrastructure.

Top Bare-Metal Hosting Providers in the USA
In a cloud-first world, certain workloads still require full control over hardware. High-performance computing, latency-sensitive …

Top 8 Cloud GPU Providers for AI and Machine Learning
As AI and machine learning workloads grow in complexity and scale, the need for powerful, …

How ManageEngine Applications Manager Can Help Overcome Challenges In Kubernetes Monitoring
We tested ManageEngine Applications Manager to monitor different Kubernetes clusters. This post shares our review …

AIOps with Site24x7: Maximizing Efficiency at an Affordable Cost
In this post we'll dive deep into integrating AIOps in your business suing Site24x7 to …

A Review of Zoho ManageEngine
Zoho Corp., formerly known as AdventNet Inc., has established itself as a major player in …
