Infrastructure drifts aren't like Pokemons you can't catch 'em all
in DevOps , Provisioning , DevSecOps , Monitoring and Observability , Error Tracking

This blog post is a written transcript of the FOSDEM Talk: “Infrastructure drifts aren’t like Pokemon, you can’t catch ’em all”, by Stephane Jourdan – CTO and founder
This talk covers three major topics:
- Infrastructure as Code: all the good intentions and the ideal world each of us expected when we started using it, and how it’s actually going in everyday’s Ops life. We will see that how it started is probably different from how it is going and from what we expected.
- We will then “drift” together, using Terraform and AWS and share some war stories that we heard from infrastructure teams, and how things sometimes went really wrong for them.
- We will finally present driftctl, our open source answer to infrastructure drift problems.
Infrastructure drift: definition
Let’s first agree on what is infrastructure drift: infrastructure drift is what happens when the reality of your infrastructure doesn’t match your expectations. This phenomenon is also known as “Oh my god” in production when things unexpectedly go wrong.
Infrastructure as code: an ideal world
How it all started
When it all started, we had this vision of an ideal world, and a bright future that Infrastructure as Code was to offer us, like Plato’s Republic was for society a while ago.

With Infrastructure as code, we were supposed to have one single source of truth (the state file in the case of Terraform).
We were supposed to have versioning of the code with git. The code was to be so great that it would be self-documenting.
In this ideal world, we would have testing everywhere: on the pipelines before and after tdd and bdd etc, like the rest of engineering. Collaboration would be a bliss between teams. Infrastructure would be immutable: we could scale it up and down and throw the rest away.
GitOps would be everywhere: CI/CD for infrastructure, no more locally running things. And basically all the credentials would be under control and multi-cloud would solve all our problems because you know what they say: “API everywhere”… and we would have the skills to handle all those APIs, and the time to do this greatly.
How it is actually going
Marcus Aurelius, the roman emperor a few centuries after Plato wrote to himself: “Do not expect Plato’s ideal Republic”. As it happens we are not Roman emperors but our ideal Republic is not to be expected either. How it started is not exactly how we see it going.
In our team, many of us were quite experienced but we wanted more feedback on what we were building. So we just asked hundreds of infrastructure teams, SREs… etc around the world where they were standing in their Infrastructure as Code journey.
Basically what they told us was that changes were still happening outside of their Infrastructure as Code: mainly manual changes and scripts that are changing tags, or lambdas updating things after deployment, etc… A lot of changes are still happening outside of their Infrastructure as Code scope, be it Terraform or Pulumi or whatever infrastructure tool they use, it doesn’t matter.
Do not expect Plato's ideal Republic
Marcus Aurelius
A bunch of other things go wrong for them as well.
The scope of their changes is not very often fully committed because of broken processes.
People are still changing things manually on their AWS web console and then backporting the changes in Terraform until Terraform starts “screaming”, which means that people are still running Terraform locally with the right access keys on their own laptop. Terrible processes… and everybody knows that once you click everywhere on your console, a lot of other things are deployed on the background and so your Terraform code doesn’t reflect exactly what’s actually deployed online.
Many people we talked to were aware of the good practices about testing requirements. They knew frameworks like Terratest, etc… but most of them never had the time to either learn or write those tests. Sometimes they were just too costly to run for them.
The lack of communication obviously makes things worse: even in these Covid19 times, “Async” communication is still a major issue between teams.
Immutable infrastructure also is still a great struggle to achieve. A lot of the new projects are running more or less around this principle, but people also still have legacy to deal with, like thousands of VMs running every day.
Lots of people are still gaining console access. And guess what ? People with AWS console access tend to change things unless you lock them down completely, which is sometimes just not possible because they are your boss or your customer, or because they are “this very special co-worker” who needs to do “that special thing” manually on the web console… That’s where problems happen.
Many people are also facing skill issues. For example, if a full team very skilled on GCP has a new project that for some reason needs to run on Azure, as all the specifics of this provider are not immediately mastered, they often end up with bad practices in their Infrastructure as Code deployments.
And basically for lots of them, everything that has an API is still not under infrastructure code: we heard terrible stories about GitHub accesses, or DNS records or anything that can be used with Terraform that wasn’t yet by far deployed with it.

Drift happens
All those behaviors have something in common: they generate drift. While drift is pretty cool for cars, the discrepancy between intention and reality can lead to major issues, disasters, or security misconfiguration. Drift can be a real major pain. To deal with it, most of the people that we met put something in place like terraform plan and apply in a cron tab or in CI/CD somewhere before and after some commits, but were still missing things.
$ terraform apply
Apply complete! Resources: 0 added, 0 changed, 0 destroyedWe love Terraform and all Hashicorp products.
Terraform is an excellent provisioner but it’s not fair to use it for something it’s not meant to do. If anything is outside its scope, it’s just normal that Terraform doesn’t catch it. There are a lot of changes that cannot be seen by Terraform.
Many of us expected terraform plan in cron tabs or in CI/CD to report changes because some of the resources were managed by it, but unfortunately as we are going to see, it is not always the case.
Stories from the trenches
The following stories are based on real stories that we heard while interviewing infrastructure teams. We simplified them to make them easy to understand with some code.
How an intern with read-only access ended up with rogue administrative access and keys(without anyone noticing)
The first story is about an intern with read-only access, ending up with access keys controlled by no one. Those keys were linked to an administrative policy, which nobody noticed. To gain a better understanding of this story, let’s look at this very simple Terraform configuration file:

We have a user with a key and a policy attachment for read-only.
Let’s apply this configuration:
$ terraform apply
Apply complete! Resources: 9 added, 0 changed, 0 destroyedNow let’s move to the AWS console: here we can see again this intern user and the key that was created by our own code.

The story goes like this:
This intern went to the DevOps folks and complained that he couldn’t use his key for whatever reason. The team was in a rush, so they quickly logged in to the management console, they deactivated the first key and created a new one, perfectly sure they were going to remember it and add it to Terraform in just a few moments. On top of that, Terraform was to notify them if they forgot anyway.

What do you think happened? Let’s check with a terraform apply on this user.
$ terraform apply
Apply complete! Resources: 0 added, 0 changed, 0 destroyedBasically nothing…
While this very simple use case may have led you to think that this specific key and user would be noticed and reported it was not the case.
So the story continues with this intern: the intern comes back one hour later complaining that he still couldn’t do what he needed to do. As the infrastructure team did not have the time to look into it, they just gave him administrative access so that he could change whatever he needed to, thinking they would revert through his permissions quickly after.

What do you think Terraform found in this case with a terraform apply , as we have a policy attached to the IAM user and everything is managed by terraform?
This team was sure that this was to be reported in terraform plan or terraform apply. But it wasn’t the case because basically it’s out of the control of Terraform. It’s just an attached resource, it doesn’t work like that.
$ terraform apply
Apply complete! Resources: 0 added, 0 changed, 0 destroyedSo the team forgot about it, they went on with the day and it was only weeks after that they realized they had an intern with an administrative key out there in the wild, uncontrolled by anyone, not even mentioned as “deactivated” on the code.
How an intern with rogue Administrative access opened everything to anyone on IPv4 and IPv6
(still without anyone noticing)
The next story starts with a process: as you know, you can have lambdas, scripts etcetera that have administrative access to some resources on a very limited scope. In this case someone with an administrative access just opened everything to anyone on IPv4 and IPv6 and no one noticed anything. So how did it go?
Let’s go into the console > VPC > us-east-1 > Security groups

So we have our super secure security group that we created using Terraform, with a rule that is attached to it.


As we can see in the AWS console, we have our “super secure security group” and we have our ssh rule for allowing ssh to this local network
For the sake of simplicity we are doing this demo manually here, but someone or something could change this specific super secure security group and could allow anything anywhere on any kind of networks on IPv4 etc… and name it very, very carefully “temp” (you know, like those temporary rules that we’ll remember soon to change…)

So what happened here is that something, with the correct access rights allowed anything to anywhere on this network behind this security group.

This team expected any kind of rules that was added or modified to be reported on terraform and while it is true for a rule it is not true for anew rule and basically the support team went weeks or months with such a rule live on their system without any notification.
$ terraform apply
Apply complete! Resources: 9 added, 0 changed, 0 destroyedHow a scripting issue created a billing nightmare
Our last story is about a team that was building a lot of stuff on S3. They were putting a lot of their binaries there and removing them. So obviously they removed the versioning.
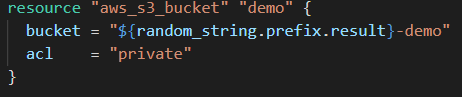
For some reason (long story short) someone activated versioning on all the buckets for the company including this one but they were pretty sure that it wasn’t going to be an issue because it’s the default on Terraform to not be versioned. But the code didn’t explicitly say it so.
Let log in on the AWS console and go to S3> bucket
Now we are on this bucket that we created using the terraform code above, and basically we are going do manually what they did through script: we are just going to enable bucket versioning.

So now Bucket versioning is enabled. Let’s check with a terraform apply what was reported:
$ terraform apply
Apply complete! Resources: 9 added, 0 changed, 0 destroyedNothing. So this poor team versioned for weeks hundreds and hundreds of terabytes a day of binaries until they received the bill…
Solutions at hand
There are a lot of solutions in our ecosystem to work around the kind of things that we just saw:
- CI/CD Integration (Jenkins, Terraform Cloud, Atlantis, env0…)
- Static Analysis (Checkov, TFLint, TFSec,…) are there to help you analyze your code before you actually push to your CI system (or if they are deploying the CI/CD systems, they are there to prevent you to push things like “allow anything to anyone” directly on the code)
- Testing & Verification like Terratest (written in Go), InSpec (for the “older” of us, it’s written in Ruby and comes from the Chef days).
- Policy & Compliance (Sentinel…) They are a very different set of tools, very cool and very protective.
Driftctl
That’s where drift control enters: we built driftctl to manage this drift and be alerted on all the discrepancies between the state and the reality on the AWS accounts.

Let’s just use the same terminal and the same session that we had previously. drift control will basically report you all the changes that you could not see with terraform plan or terraform apply.
$ driftctl scan --from tfstate://./s3/terraform.tfstate --from tfstate://./vpc/terraform.tfstate --from tfstate://./iam/terraform.tfstate
Terraform provider initialized (name=aws, alias=us-east-1)
Terraform provider initialized (name=aws, alias=eu-west-3)
Terraform provider initialized (name=aws, alias=eu-north-1)
Found deleted resources:
- Table: rtb-0c5a9bb483ee6eaaf, Destination: 10.0.1.0/24
Found unmanaged resources:
aws_security_group_rule:
- Type: ingress, SecurityGroup: sg-0746ca93f95fcc338, Protocol: All, Ports: All, Source: ::/0
- Type: ingress, SecurityGroup: sg-0746ca93f95fcc338, Protocol: All, Ports: All, Source: 0.0.0.0/0
aws_iam_access_key:
- AKIASBXWQ3AYRSNQN5EY (User: INTERN-8mszmf)
Found drifted resources:
- AKIASBXWQ3AYWWYX72GX (User: INTERN-8mszmf) (aws_iam_access_key):
~ Status: "Active" => "Inactive" (computed)
Found 26 resource(s)
- 84% coverage
- 22 covered by IaC
- 3 not covered by IaC
- 1 deleted on cloud provider
- 1/22 drifted from IaCNow, we can see the rules that allowed “anything to anywhere” on IPv4 and IPv6 and we know that there are rules that were not expected.
We also have the policy attachment of that intern we talked about.
So probably with your eyes of administrative people, DevOps, whatever you are, it doesn’t match. It should ring a bell that something is wrong here actually: what about this new access key? Even if you’re not a security person, if you have a new access key created out of nowhere, reported to you, this should ring a bell.
Let’s go ahead and create a new bucket and call it “Fosdem 2031”.

Obviously this bucket is not in Terraform because we just created live on the console. It’s perfectly normal for Terraform not to report you that this specific bucket was created right now. But this is the job of driftctl to report that you have both unmanaged resources that were created and deltas from managed resources.
$ driftctl scan --from tfstate://./s3/terraform.tfstate --from tfstate://./vpc/terraform.tfstate --from tfstate://./iam/terraform.tfstate
Terraform provider initialized (name=aws, alias=us-east-1)
Terraform provider initialized (name=aws, alias=eu-west-3)
Terraform provider initialized (name=aws, alias=eu-north-1)
Found deleted resources:
aws_route:
- Table: rtb-0c5a9bb483ee6eaaf, Destination: 10.0.1.0/24
Found unmanaged resources:
aws_s3_bucket:
- fosdem2031
aws_security_group_rule:
- Type: ingress, SecurityGroup: sg-0746ca93f95fcc338, Protocol: All, Ports: All, Source: ::/0
- Type: ingress, SecurityGroup: sg-0746ca93f95fcc338, Protocol: All, Ports: All, Source: 0.0.0.0/0
aws_iam_access_key:
- AKIASBXWQ3AYRSNQN5EY (User: INTERN-8mszmf)
Found drifted resources:
- AKIASBXWQ3AYWWYX72GX (User: INTERN-8mszmf) (aws_iam_access_key):
~ Status: "Active" => "Inactive" (computed)
Found 27 resource(s)
- 81% coverage
- 22 covered by IaC
- 4 not covered by IaC
- 1 deleted on cloud provider
- 1/22 drifted from IaCLet’s focus on the VPC here: if we change an existing rule…
… we can see it in the diffs in driftctl
$ driftctl scan --from tfstate://./s3/terraform.tfstate --from tfstate://./vpc/terraform.tfstate --from tfstate://./iam/terraform.tfstate
Terraform provider initialized (name=aws, alias=us-east-1)
Terraform provider initialized (name=aws, alias=eu-west-3)
Terraform provider initialized (name=aws, alias=eu-north-1)
Found deleted resources:
aws_route:
- Table: rtb-0c5a9bb483ee6eaaf, Destination: 10.0.1.0/24
Found unmanaged resources:
aws_s3_bucket:
- fosdem2031
aws_security_group_rule:
- Type: ingress, SecurityGroup: sg-0746ca93f95fcc338, Protocol: All, Ports: All, Source: ::/0
- Type: ingress, SecurityGroup: sg-0746ca93f95fcc338, Protocol: All, Ports: All, Source: 0.0.0.0/0
aws_iam_access_key:
- AKIASBXWQ3AYRSNQN5EY (User: INTERN-8mszmf)
Found drifted resources:
- AKIASBXWQ3AYWWYX72GX (User: INTERN-8mszmf) (aws_iam_access_key):
~ Status: "Active" => "Inactive" (computed)
aws_S3_bucket:
-fosdem2031
Found 14 resource(s)
- 50% coverage
- 7 covered by IaC
- 4 not covered by IaC
- 1 deleted on cloud provider
- 1/14 drifted from IaCThe other things we can do with drift control is ignore some resources that you do not want to see reported for whatever reason you have.

So you can also filter using the same system as AWS CLI. For example, you can filter just for S3 buckets if you are not interested in the rest.
$ driftctl scan --filter "Type=='aws_s3_bucket'"$ driftctl scan --from tfstate://./s3/terraform.tfstate --from tfstate://./vpc/terraform.tfstate --from tfstate://./iam/terraform.tfstate --filter "Type=='aws_s3_bucket'"
Terraform provider initialized (name=aws, alias=us-east-1)
Terraform provider initialized (name=aws, alias=eu-west-3)
Terraform provider initialized (name=aws, alias=eu-north-1)
Found unmanaged resources:
aws_s3_bucket:
- fosdem2031
Found 2 resource(s)
- 50% coverage
- 1 covered by IaC
- 1 not covered by IaC
- 0 deleted on cloud provider
- 0/1 drifted from IaCIt’s pretty cool for auditing purposes, for monitoring purposes etc…
And that's a wrap!
Thank you very much for reading through all this talk transcript.
If you wish to gain a better understanding of driftctl, please visit our product page or our advanced tutorial. We also have a series of short demo videos that you can watch to get started in minutes.
For any questions, feel free to open a discussion on GitHub or visit us discord.
Get similar stories in your inbox weekly, for free
Share this story:

driftctl
Infrastructure as code is awesome, but there are so many moving parts: codebase, *.tfstate , actual cloud resources. Things tend to drift. driftctl is a free and open-source CLI that tracks, analyzes, prioritizes, and warns of infrastructure drift
Published by
Infrastructure as code is awesome, but there are so many moving parts: codebase, *.tfstate , actual cloud resources. Things tend to drift. driftctl is a free and open-source CLI that tracks, analyzes, prioritizes, and warns of infrastructure drift

Latest stories

Best Cloud Hosting in the USA
This article explores five notable cloud hosting offers in the USA in a detailed way.

Best Dedicated Hosting in the USA
In this article, we explore 5 of the best dedicated hosting providers in the USA: …


The best tools for bare metal automation that people actually use
Bare metal automation turns slow, error-prone server installs into repeatable, API-driven workflows by combining provisioning, …

HIPAA and PCI DSS Hosting for SMBs: How to Choose the Right Provider
HIPAA protects patient data; PCI DSS protects payment data. Many small and mid-sized businesses now …

The Rise of GPUOps: Where Infrastructure Meets Thermodynamics
GPUs used to be a line item. Now they're the heartbeat of modern infrastructure.

Top Bare-Metal Hosting Providers in the USA
In a cloud-first world, certain workloads still require full control over hardware. High-performance computing, latency-sensitive …

Top 8 Cloud GPU Providers for AI and Machine Learning
As AI and machine learning workloads grow in complexity and scale, the need for powerful, …

How ManageEngine Applications Manager Can Help Overcome Challenges In Kubernetes Monitoring
We tested ManageEngine Applications Manager to monitor different Kubernetes clusters. This post shares our review …

AIOps with Site24x7: Maximizing Efficiency at an Affordable Cost
In this post we'll dive deep into integrating AIOps in your business suing Site24x7 to …

A Review of Zoho ManageEngine
Zoho Corp., formerly known as AdventNet Inc., has established itself as a major player in …
