OpenShift 4 “under-the-hood”
in Kubernetes , Orchestration

This blog walks through some of the critical architectural decisions and components of OpenShift 4.x
I have been playing around with Red Hat OpenShift 4.x for the past few months now… It has been a super exciting learning journey…In this blog, I will attempt to capture the key architectural components of OpenShift 4.x and how they come together, to provide the most comprehensive container platform.
… let's open the hood…
Nuts and Bolts
Built on CoreOS: According to me, this is one of the major architectural changes in OpenShift 4.x. and I think it really changed the way platform works…here is how!!!
CoreOS provides “immutability”!!!…what does that even mean…let me explain…while Red Hat CoreOS is built on RHEL components (brining in all the security and control measures)..CoreOS allows you to modify only a few system settings, and make it much easier to manage upgrades & patches. This immutability allows OpenShift do better state management and perform updates based on the latest configurations.
so what's the big deal??..here are the top reasons, why I think its a big deal
- Versioning and rollbacksof deployments are much easier & straight forward — so the DevOps process is much more manageable.
- “Configuration Drift” is a big issue, if you have managed a large number of containers/MicroServices, in a HA/DR environments. Typically container infrastructure is built by a team and over a period of time is managed by various engineers. There are always situations, where we are forced to change the configuration of the VMs/Containers/OS, that we may never trace back.
- This causes a gap between Production & DR/HA environment. I read somewhere that up-to 99%of HA/DR issues are caused due to this..and in my experience a Core Banking System, went down for days, before we could even figure out that the root-cause was configuration gaps between Prod & HA/DR.
- Immutability helps us do better version control of the infra — We will have moreconfidence in testing, as the underlying infrastructure on which our application containers are running, is immutable, and we are very sure about the test results, and more confident.
Vertically Integrated stack with CoreOS: In OpenShift 4.x, CoreOS is vertically integrated with the Container platform…what it means is that the cluster can now manage the pools of Red Hat CoreOS machines (nodes), and its full lifecycle, in k8s style!!!. Imagine how it will reduce the operational effort!!!, just to compare with OpenShift 3.x — we used to manually provision OS and rely on the administrators to configure the OS properly and more importantly manage the updates & upgrades.
To my earlier point, this also caused a lot of issues due to “Configuration Drifts” over a period of time…you will see how this vertical integration will help setup & manage Nodes as “Machines” later in the blog.
 OpenShift 4
OpenShift 4
CRI-O as the container runtime: I had published a blog on “why CRI-O”…please read this blog. But in my personal opinion, this is another very critical architectural decisions that make OpenShift 4.x more agile, light-weight, scalable, and high performing container platform.
Operators: This is another important component of the architecture…which allows us to extend the k8s and customize the resources and controllers & and build a more manageable system…please read my blog on operators, where I go deeper.
Machine Management: Machine Management is one of the most important ecosystem of resources & operators in OpenShift 4.x. These resources and operators provide a comprehensive set of APIs for all node host provisioning & works with the Cluster API for providing the elasticity & autoscaling
- Machine: Machine is the fundamental unit that represents the k8 node, which abstracts the cloud platform “specific” implementations. The machine “providerSpec” describes the actual compute node, that gets realized. MachineConfig defines the machine configuration,
- MachineSets: Like how replicaSets manage the replicas, and ensure and maintain the “Desired state”, MachineSet ensure the desired state of a number of machine (nodes) that are running
- MachineAutoScaler: MachineAutoScaler works with MachineSets to manage the load and automatically scale the cluster. The minimum and maximum number of machines are set in MachineSet, and MachineAutoScaler manages scalability
- ClusterAutoScaler: This ClusterAutoScaler manages the cluster wise scaling policy based on various cluster-wide parameters such as cores, memory, GPU, etc.
As we walk through the blog, you will see more and more nuts and bolts coming together to build the most advanced container platform
Provisioning
OpenShift 4.x introduced a more sophisticated and automated installation procedure, called Installer-provisioned Infrastructure, which does a full-stack install — leveraging the Ignition & Operator. There are 2 ways to install
Installer-provisioned Infrastructure (IPI): This is only available for OpenShift 4.x, This provides a full-stack installation and setup of the cluster, including the cloud resources and the underlying Operating system, which in this case is RHEL CoreOS.
User-Provisioned Infrastructure (UPI): UPI is the traditional installation, that we had since OpenShift 3.x, where we need to set up the underlying Infrastructure (Cloud Resources & OS), and openshift-install can help automatically set up the cluster & cluster services.
 Provisioning
Provisioning
Apart from this, OpenShift is also available as a managed service offered by most of the hyper-scalers IBM, AWS, Azure, GCP
Ignition is the most important utility, that has powerful capabilities to manipulate disks during the initial setup, it reads from the configuration files (.ign) and creates the machines, It makes the provisioning process, super easy…
Lets now see how the Ignition works in setting up the full cluster.
 how the Ignition works in setting up the full cluster
how the Ignition works in setting up the full cluster
In the above picture, you can see how Ignition configuration files (.ign) are used by the bootstrap machine (read machine=node in OpenShift 4.x), that spins off the master nodes, replicates etcd, merging the base ignition configuration and any other user customized configurations, which in turn spin off the worker nodes, using worker and master configurations.
Updates & Upgrades
OpenShift 4.x provides seamless updates, over-the-air. This is possible because of the integrated CoreOS, and the magical MachineConfig Operator. Here is how it works
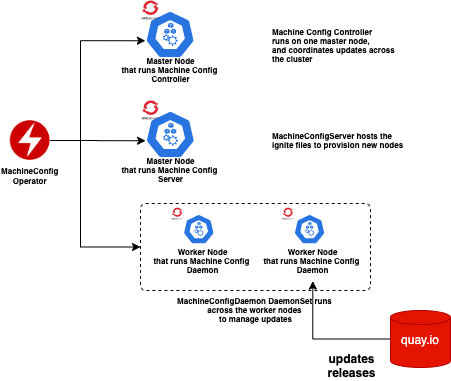
MachineConfig Operator manages the configuration changes across the cluster. Before we try to understand how the updates and upgrades, let's understand the key components of this Operator, that come together
- MachineConfig Controller: This runs on master and orchestrates updates across clusters.
- MachineConfigServer: This hosts the ignition config files, that provision any new nodes.
- MachineConfig Daemon: This runs on every worker machine (its a daemonset), and is responsible to manage updates on worker machines.
- MachineConfig is a k8s object, that is created by bootstrap ignition, and it represents the state of the machine.
- MachineConfigPool is the group of machines of a particular type., like a master machine, worker machine, infrastructure machine etc.
 Updates & Upgrades
Updates & Upgrades
The changes to the system happens through the changes in the MachineConfig. Any changes in the MachineConfig is rendered and applied to all the machines in a MachineConfigPool.
So if I have to change a configuration of a type of machine (node), I apply the change to the MachineConfig, which is picked up by MachineConfig Controller, that co-ordinates with MachineConfig Daemons.
The MachineConfig Daemons, pulls the MachineConfig changes, from the API server, and applies to their respective machines (nodes). If the change is an upgrade, it would connect to the quay.io registry to pull the latest image, and applies it.
MachineConfig Daemons sequences and drains the node/machines, and reboots them, after applying the changes...
The updates can be applied OTA (over-the-air) using either the admin console or cloud.openshift.com web interface. The release artifacts are packaged as container images, as a single package. ClusterVersion Operator, checks with OCP Update Server (hosted by Red Hat), and then connects to the Red Hat hosted Quay.io, to pull the image, and works with Cluster Operators for rolling out the upgrades.typical application level upgrades are managed by OLM operators
…and that is how OpenShift provides a sophisticated & controller way to do the updates and upgrades across the cluster.
Runtime
Now, let's explore how OpenShift 4 architecture looks in runtime…The below diagram shows how the Master and Worker nodes are stacked…
 Openshift master and worker nodes
Openshift master and worker nodes
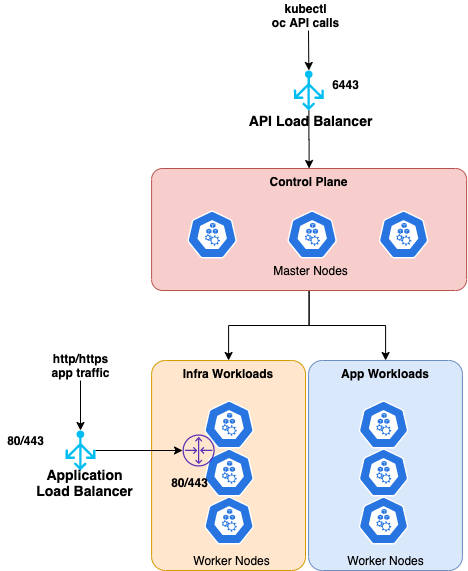
…and the below diagram, illustrates how the deployment architecture looks at a high-level…if you look closer, the Infra workloads are provisioned separately, from the app workloads. This helps in reducing the load on the application worker machine. The Infrastructure MachineSet takes care of
 how the deployment architecture looks at a high-level
how the deployment architecture looks at a high-level
Just to make more practical sense of the above diagram, if you run an IPI on AWS…here is a how the typical cluster would look like, from the topology perspective…
- 6 EC2: 3xMaster nodes, 3xWorkers nodes
- 2 Route53 Configurations: 1xAPI Server, 1xApp domain
- 3 ELB: 1xInternal API Load balancer, 1xExternal API Load balancer: 6443 port traffic is the target group of 3 masters — API traffic, 1xApplication Load balancer — This is configured to 3 worker nodes
- 2 security groups: One for master, One for worker
- All of them in a VPC
you can see a detailed AWS deployment architecture here, similarly, you can refer to the respective hyper scalers.
Scaling
OpenShift 4.x out-of-the-box supports both auto and manual scaling. Each of the nodes are configured as Machine resources, and the MachineSet manages multiple machines.
One MachineSet is configured per availability zone. MachineSet ensures the “desired state” of the number of machines (nodes).
In the case of manual scaling, The MachineSet configurations can be edited to increase the number of machines.
In case of auto-scaling, MachineAutoScaler automatically scales the MachineSet desired state up and down, and limits between the minimum and maximum number of the machine that is configured, and ClusterAutoScaler decides the scaling up and down based on various parameters such as CPU, memory, etc. All of this works independently of underlying cloud infrastructure!!! 😎. The diagram below illustrates how it works.
 How OpenShift scaling works
How OpenShift scaling works
DevOps
Now moving to the most important part of the SDLC — DevOps. There are 2 key components that help improve the developer experience for rapid development and deployment in OpenShift 4.x
CodeReady Workspace
CodeReady workspace is based on Eclipse Che, which brings a completely integrated web-based development environment and seamless integration with the OpenShift platform. It also comes pre-packaged with various development environment template for polyglot development & deployment. How cool is that!!!
Native CI/CD
Moving beyond Jenkins, OpenShift 4.x brings the cloud-native CI/CD with Tekton, which runs within K8s. Tekton runs completely serverless, with no extra load on the system.
I will be covering more in detail about Tekton and GitOps soon in a separate blog, will leave a link, here once done!!!
Both CodeReady Workspaces and Tekton and pipelines are available as Operators in OperatorHub…so just click and install…
Day 2 - Ops
Managing cloud application is the most critical, as the number of MicroServices grow, and the deployments grow, it becomes very important to have a integrated management platform, that supports
- Observability (with Grafana and Prometheus)
- Traceability (with Kiali and Jaeger)
- Canary Deployments & Rolling Updates (with Istio)
- API routing & Management (with Istio )
 OpenShift ServiceMesh
OpenShift ServiceMesh
OpenShift ServiceMesh provides a complete management solution, that is highly extendable to integrate with the larger enterprise Ops…also check out my other blog on Operators, on how we can achieve zero-touch ops here
There you go..this is really the enchilada of container world 🌐
This is not all, there is a lot more, such as: how OpenShift abstracts the storage with Red Hat OpenShift Container Storage, and how it abstracts the underlying cloud platform network with Networking Operator- CNO and CNI, and the most important feature of Multi-cluster management.
I will soon be publishing a blog on Multi-cluster management, I will be covering in detail, and will be leaving a link on the blog, when published…
phew!!! that's a lot for one blog…
I hope it now makes sense, why we need a container platform like OpenShift…imagine, it will be a nightmare if I had to “DYI” with k8s and a bunch of OpenSource libraries. 😳
The only downside of OpenShift is that it is an “opinionated full-stack” platform…if you think about it!!! we need a container platform to run business-critical workloads..(personally, I always love to build my own stack, and play around with it…but can’t risk experimenting with serious enterprise applications)
in the meantime…you can play around with OpenShift with a free trial, or install it on ur laptop with CodeReady Containers from here (your laptop might need a good cooler :-) )…
Enjoy!!! stay safe..ttyl…
Get similar stories in your inbox weekly, for free
Share this story:

Vijay Kumar A B, IBM Distinguished Engineer @ IBM
AB Vijay is a IBM Distinguished Engineer & CTO for CAS Manage & Application Innovation Lab. He is a IBM Master Inventor, who has more than 58 patents filed in his name. He has more than 22 years experience in IBM. He is a recognized as subject matter expert for his contribution to advanced mobility in automotive, and has led several implementation involving complex industry solutions. He specializes in mobile, cloud, containers, automotive, sensor-based machine-to-machine, Internet of Things, an
Published by
AB Vijay is a IBM Distinguished Engineer & CTO for CAS Manage & Application Innovation Lab. He is a IBM Master Inventor, who has more than 58 patents filed in his name. He has more than 22 years experience in IBM. He is a recognized as subject matter expert for his contribution to advanced mobility in automotive, and has led several implementation involving complex industry solutions. He specializes in mobile, cloud, containers, automotive, sensor-based machine-to-machine, Internet of Things, an

Latest stories

Best Cloud Hosting in the USA
This article explores five notable cloud hosting offers in the USA in a detailed way.

Best Dedicated Hosting in the USA
In this article, we explore 5 of the best dedicated hosting providers in the USA: …


The best tools for bare metal automation that people actually use
Bare metal automation turns slow, error-prone server installs into repeatable, API-driven workflows by combining provisioning, …

HIPAA and PCI DSS Hosting for SMBs: How to Choose the Right Provider
HIPAA protects patient data; PCI DSS protects payment data. Many small and mid-sized businesses now …

The Rise of GPUOps: Where Infrastructure Meets Thermodynamics
GPUs used to be a line item. Now they're the heartbeat of modern infrastructure.

Top Bare-Metal Hosting Providers in the USA
In a cloud-first world, certain workloads still require full control over hardware. High-performance computing, latency-sensitive …

Top 8 Cloud GPU Providers for AI and Machine Learning
As AI and machine learning workloads grow in complexity and scale, the need for powerful, …

How ManageEngine Applications Manager Can Help Overcome Challenges In Kubernetes Monitoring
We tested ManageEngine Applications Manager to monitor different Kubernetes clusters. This post shares our review …

AIOps with Site24x7: Maximizing Efficiency at an Affordable Cost
In this post we'll dive deep into integrating AIOps in your business suing Site24x7 to …

A Review of Zoho ManageEngine
Zoho Corp., formerly known as AdventNet Inc., has established itself as a major player in …
