Having On-call Nightmares? Runbooks can Help you Wake Up.

You aren't sure how long you've been here, but the view outside the window sure is soothing. Before you can fully take in your surroundings, a siren rips you back into the conscious world. Slowly, you begin to piece together that you exist, and you are on call.
By: Harry Hull
The nightmare
You aren't sure how long you've been here, but the view outside the window sure is soothing. Before you can fully take in your surroundings, a siren rips you back into the conscious world. Slowly, you begin to piece together that you exist, and you are on call.
The ringing, much louder now, pierces through your skull as you begin to open your bleary eyes. You turn over your pillow, grab your phone, and click through the PagerDuty notification. After quickly ACKing, you start to read the alert:
alertname = CartService5xxError
As fate would have it, you know literally nothing about the cart service or why it might be erroring. Unfazed, you keep reading:
endpoint ='CheckoutPromoWeb'
This combination of symbols is totally meaningless to you, but its sounds really scary. You have already worked here for a year, but you acutely remember your first week when the cart service was down for 3 hours. The company lost a lot of money and your boss was really stressed out during the incident retrospective.
You read the rest of the alert message, hoping for a sign for how serious this could be:
description = ask harry
"Great... I’ll page Harry," you mumble under your breath as you reach for your laptop. What your half-asleep brain fails to realize is that Harry hasn't worked at the company for 4 years.
You will soon realize this, however, as you sit hunched over your laptop staring at a greyed out "deactivated" Slack avatar. No one else is awake either, of course, and in a hazy panic you `@channel` your entire team and page a few unfortunate people.
In the meantime, you start to open random dashboards searching for any clues to help triage the severity of this mess.
There's a better way
The previous spooky tale is sadly all too real. After a short time on call, every team realizes that having service alerts is only the very first step. There's a huge gap between having well-instrumented services with actionable alerts and having your alerting system so finely tuned that anyone on the team can ack and efficiently act upon an alert, even with a sleep deprived mind.
To get to the latter point, try to get your team to consider the following questions for different scenarios:
- Is this currently affecting our customers? Will customers be affected soon? If so, how many and how bad?
- Has this happened before? What did we do?
- What other context do I need to fully triage this?
- How do I know when this has recovered?
In order to bridge this gap and answer these questions, we created Runbook Documentation. Now we link a runbook in the description of all of our alerts, and we don't let a new alert get passed the pull request without an attached runbook. This is how we ensure our on-call team feels supported, even during the trickiest of incidents.
Applying a runbook to incident response
In the beginning of our story, the first thing the on-call needed to do is triage the customer impact of the alert. Since it's hard to remember anything at 2:30 AM, this is our first step in the runbook.
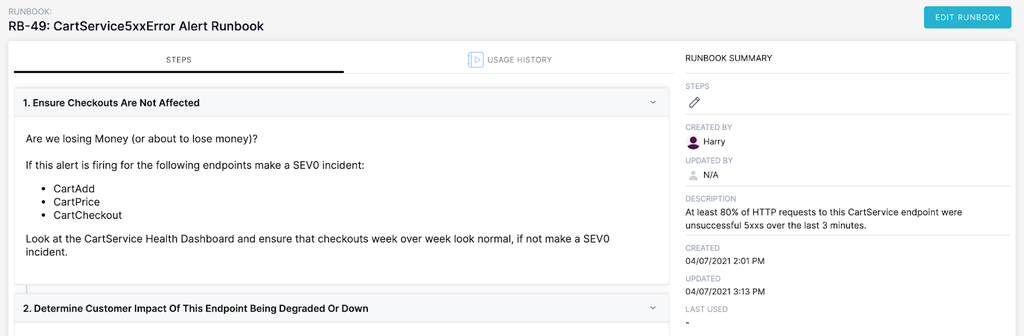 Runbook Step 1 of Waking up From an On-Call Nightmare
Runbook Step 1 of Waking up From an On-Call Nightmare
This step links to a dashboard showing the general health of the cart service (request / error throughput + latency histograms). Here, the on-call can quickly see some very important context: how many purchases are happening, and which endpoints are erroring at what rate.
 Dashboard showing the general health of the cart service
Dashboard showing the general health of the cart service
Now the on-call can see that, thankfully, checkouts per minute are about the same as this time last week and there are no huge dips. This isn't affecting revenue yet, but we still don't know how these errors are affecting the customer experience.
Step 2 gives context to show the customer impact of this endpoint being down, and links to additional runbooks if necessary. This step could also give an updated severity recommendation for the incident based on impact.
 Runbook Step 2 of Waking up From an On-Call Nightmare
Runbook Step 2 of Waking up From an On-Call Nightmare
Now we know that customers will not be able to see offers on the checkout page. This, of course, is frustrating to the customer and impacts revenue, but customers are still ordering and the core purchase flow is otherwise healthy. Following the runbook, the on-call creates a SEV3 incident in Blameless and continues on to the next steps.
 Runbook Step 3 & 4 of Waking up From an On-Call Nightmare
Runbook Step 3 & 4 of Waking up From an On-Call Nightmare
From here, the on-call sees a ton of experiment-related errors. They notice that all of the error logs seem to be referencing the same experiment ID. This experiment is probably the culprit for the sudden spike in errors. The linked “Promotion Outage Runbook” mentions that misconfigured experiments have caused outages in the past, and has a section on viewing historical data for experiments and steps for disabling specific experiments.
Iterating through failure
In this example, the on-call team is able to successfully resolve an incident with a handy runbook. But, how would this outcome have changed if the runbook was out of date, or even just not thorough enough in detail? A good runbook takes time and iterations for it to be maximally informative
With each outage, runbooks can be tuned and hardened to be more helpful for the people acking the alert. Keeping in line with the blameless ethos, common problems like misestimating severities can be seen as gaps in our runbooks and processes rather than the mistake of the on-calls.
Runbooks are living documents. They’re meant to be helpful. If a particular runbook is not answering the questions you need, it’s time to review it. As your runbooks improve, you’ll be able to eliminate toil from the incident response process. Additionally, some of that on-call dread will dissipate as you know that you have the tools to support you during an incident.
If you’d like to learn more about runbooks, here are some additional resources:
Get similar stories in your inbox weekly, for free
Share this story:

Blameless
Blameless is the industry's first end-to-end SRE platform, empowering teams to optimize the reliability of their systems without sacrificing innovation velocity.
Published by
Blameless is the industry's first end-to-end SRE platform, empowering teams to optimize the reliability of their systems without sacrificing innovation velocity.

Latest stories

Best Cloud Hosting in the USA
This article explores five notable cloud hosting offers in the USA in a detailed way.

Best Dedicated Hosting in the USA
In this article, we explore 5 of the best dedicated hosting providers in the USA: …


The best tools for bare metal automation that people actually use
Bare metal automation turns slow, error-prone server installs into repeatable, API-driven workflows by combining provisioning, …

HIPAA and PCI DSS Hosting for SMBs: How to Choose the Right Provider
HIPAA protects patient data; PCI DSS protects payment data. Many small and mid-sized businesses now …

The Rise of GPUOps: Where Infrastructure Meets Thermodynamics
GPUs used to be a line item. Now they're the heartbeat of modern infrastructure.

Top Bare-Metal Hosting Providers in the USA
In a cloud-first world, certain workloads still require full control over hardware. High-performance computing, latency-sensitive …

Top 8 Cloud GPU Providers for AI and Machine Learning
As AI and machine learning workloads grow in complexity and scale, the need for powerful, …

How ManageEngine Applications Manager Can Help Overcome Challenges In Kubernetes Monitoring
We tested ManageEngine Applications Manager to monitor different Kubernetes clusters. This post shares our review …

AIOps with Site24x7: Maximizing Efficiency at an Affordable Cost
In this post we'll dive deep into integrating AIOps in your business suing Site24x7 to …

A Review of Zoho ManageEngine
Zoho Corp., formerly known as AdventNet Inc., has established itself as a major player in …
