How to Cut Cloud Costs for 2021 Using Blameless

To recap, by using Blameless to drive our cloud migration and cost management projects, we were able to:
* Find ways to decrease our cloud spend by 30% per month, without refactoring
* Save an estimated 3 hours per week of meeting time per each engineer involved
* Reduce toil from collaboration with our Slackbot and automated timeline features
By: Geoff White
Blameless Incident Management is a tool for managing production incidents. However, it can support many different use cases due to its flexibility. Here at Blameless, we try to “dogfood” our product as much as possible. So we’ve taken to using the IM feature for many other aspects of our daily work, not just system outages. One use case that I’m particularly fond of is using the tool to drive alignment and collaboration around long-term infrastructure projects. In this blog post, I’m excited to share a project that I’m working on to reduce our cloud spend. Let’s take a look at some of the non-outage ways we use Blameless Incident Management to manage, track, and keep a historical record of projects that might have durations of weeks or months, versus nail-biting minutes or hours.
Our goal
Our CFO has noticed that our cloud bill with our hosting provider, GCP, has been steadily increasing on a monthly basis. He’s asked the SRE team to look into the reasons behind the trend, and come up with a strategy that will allow us to:
- Flatten the curve of increasing cost,
- Run leaner in the long term,
- And build better monitoring so that we can capacity plan.
We have our marching orders, so let’s get after it.
Setting up the incident
We have defined custom incident types for many of our long-term projects. For this project, we used the infrastructure-project custom incident type. Here’s how this custom type is defined. You can create a similar one within Blameless using this format.

To set this project apart from other incidents in Slack, we are going to use the “issue name (project-issue-id)“ naming scheme. When the incident is created, we will automatically invite all members of our Infrastructure team’s slack group. We are also going to send notifications to the SRE team’s private slack channel.
This incident is expected to last a long time (as in a few weeks to months rather than a few minutes), and will not follow the traditional incident structure of investigating, identifying, monitoring, and resolution. We used only investigation and resolution for the purposes of this long-term project. Still, we can use this structure to help us remember to do certain tasks, like assigning a communications lead, technical lead, and coordinating a kick-off meeting.
Since this is not an urgent issue, we can use a low severity level. The default we use is SEV3; however, you can always craft custom severity levels based on your organization’s definitions.
Getting everyone on the same page
Once the infrastructure project has been defined, we can kick off an incident in Blameless. This automates a lot of the busy work instantaneously. Blameless has created a Slack channel, a Zoom bridge in case we need to do face-to-face communication, as well as a JIRA tracking ticket.
Since we are now living in the “new normal” of a pandemic, many typical modes of communication such as physical meetings, white boards, and hall conversations are no longer viable. But by leveraging Blameless’ built-in IM features, we have everything we need in our current remote workplace.
When we jump over to the Slack channel, we see a banner containing the current status of our project/incident (Robot Krabs is our funny nickname for the Blameless Bot).
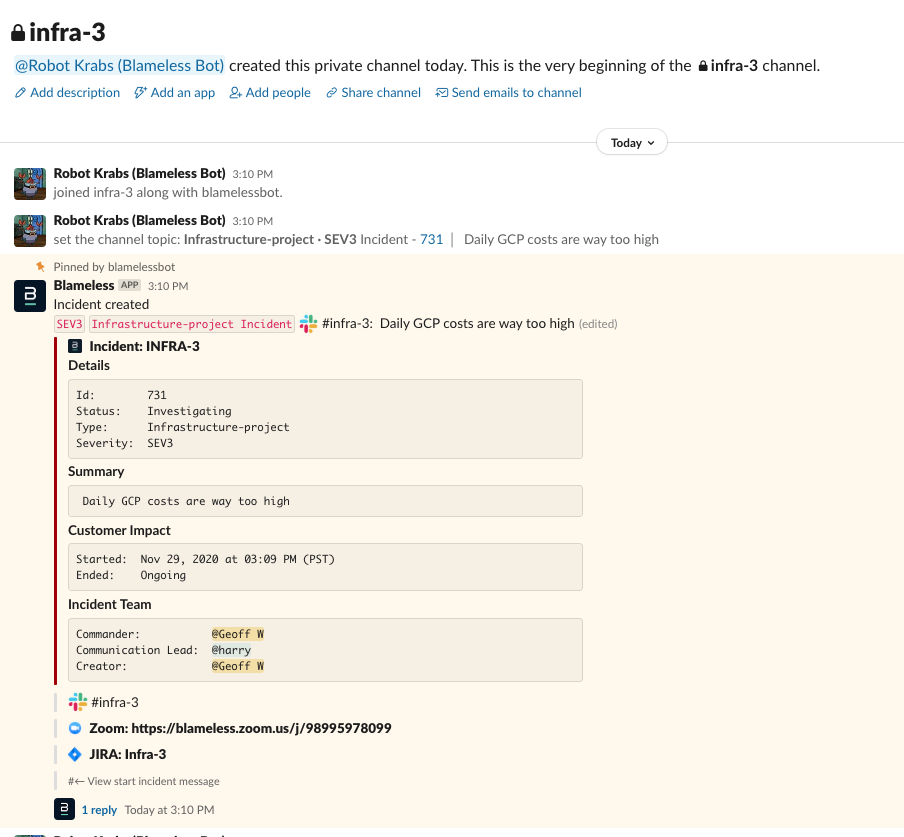
Now that the incident is under way, what next? One of the great things about using Blameless IM for project management and collaboration is its ability to enable dynamic participation. People can drop in and out of the incident as they see fit. Some may simply choose to “lurk.” People lurking (like senior management) can keep apprised of the project, but don’t need to be involved in the day-to-day project work.
There may be other stakeholders that are interested in either observing the work as it progresses or asking questions of the team. This is a great way to provide up-to-date statuses. Anyone who joins the channel can observe progress, grab a graphic or visual, or ask a question. Other technical personnel may jump into the incident to provide expertise and leave when they no longer need to contribute. Working in this asynchronous way, we can reduce the number of recurring calendar meetings. In fact, in the first 3 weeks of this project, we only had one team meeting (33% of what we would need without Blameless).
While we have our directive coming from above, the technical fine points still need to be ironed out.
One of our senior engineers, Uzair, shares an initial graph to get us talking.

Together, we decide on some next steps:
- Get access to GCP billing reports
- Compute an estimated cost per customer for prod clusters
- Compute an estimated cost per ephemeral instance
- Analyze options: i) Do away w/ ephemeral cluster, ii) Remove unnecessary resources
This is a good start, but these goals will need to evolve as the project moves forward.
Darrell, one of our SRE’s, starts to offer some preliminary suggestions. He hypothesizes that we’re maxing out our CPU requests per container, but only using about half of each node’s memory. He thinks it’s worth looking into tuning the pods to use less CPU, or buying reserved VMs at a lower price. All of these are valuable insights, and the great thing is that we can capture it all in the incident channel for record-keeping. Graphs and links are automatically tagged for inclusion in the incident timeline so anyone can refer back to it.
Working through the solutions
After a while, we begin examining ways to lower our monthly cost through our billing program. This means we’ll need to schedule some calls with our vendor.
Hopping on calls with vendors can be time consuming, and it’s tough to find a time that works for everyone. With Blameless’ IM, we can post Zoom recordings to the channel and pin them to our timeline. In fact, we’ve found that meetings where the primary purpose is knowledge transfer only need to involve at most three people. Teammates who want deeper context from the meetings can watch the recording on their own time. No need for them to attend yet another meeting. We can also post a brief recap in the channel and add that to the timeline as well. This further decreases the time we need to spend in meetings, freeing up time for high-value work like feature development.
After chatting with our vendors, and deploying some visualization tools like Google’s Data Studio, and ReOptimize, we start to see a more accurate breakdown of what we are spending, and how we’re spending it. Our most costly line item is compute power and RAM for our us-central-1 instances. Next is logging.

To get some easy wins, we deactivated some dead wood instances. We also turned off some traffic flow logs that weren’t necessary, as the information was available from one of our third party vendors for free.
Initially, we thought that we could mitigate cost by just deactivating parts of the infrastructure no longer in use. After evaluating the situation for one month, the cost graph seemed to validate this point of view.
But… it’s important to always cross check as certain cuts of data don’t always tell the full story. When we took a look at actual usage for the month of November, a different picture emerged.
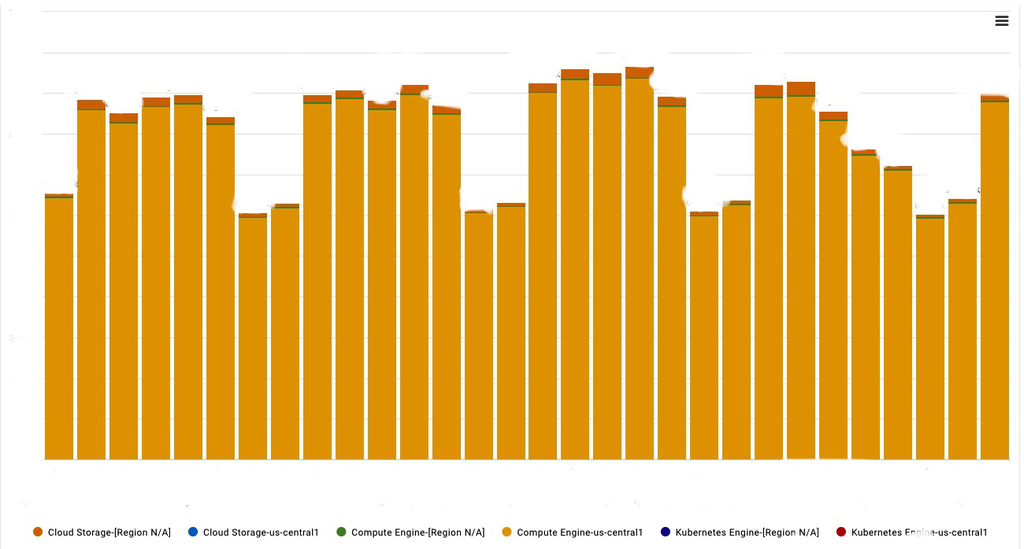
We can see that turning off dead wood only dropped our primary spend, Compute Engine, by about 10%. The decrease in our billing was actually driven by our billing plan, which yielded a 30% discount due to the sustained usage that we were achieving month after month. We could embark on engineering retooling in an attempt to make certain systems more efficient, but engineering retooling takes engineering hours, which also has high associated costs.
After some discussion, we learned that the billing restructuring would yield a 7% reduction from the current billing cycle. This method is low-risk for engineering as it is a management decision. However the recommendation is not without financial risk. To get the 7%, we need to make a one year commitment to a certain usage threshold.
This may seem like a no-brainer, but since we are basically buying a bulk of usage at a discounted rate, we are obligated to spend at a rate that is not lower than that. This could affect our efforts of building efficiency into the system. Building too much efficiency without increasing the workload could yield a situation where we are paying for infrastructure that we are not getting immediate value from.
Working with our cloud vendor, we discovered an even better solution. We could change the type of Node VMs that we deploy from N1 VMs to a cheaper VM with equivalent performance, the E2. These VMs are 30% cheaper to operate than N1 VMs. The risk is that E2 VMs are susceptible to downward performance pressure as the underlying GCP infrastructure becomes more heavily loaded. The most easy way to explain this is with the following table.
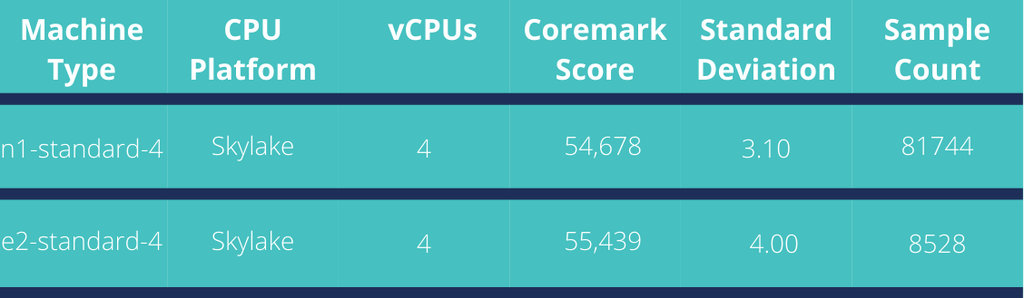
Both VM types run on the same processor platform and their coremark scores are essentially the same, the STD (standard deviation) for the E2 is higher by .9 percentage points over the N1. Our workload is CPU-intensive but this difference is tolerable for most of our workloads. The Nodes that require more guarantee of consistent response time, like our Prometheus monitoring infrastructure, can remain on N1 class VMs.
In the meantime, we’ll start to evaluate using the more economical E2 images, replacing our current, more expensive N1 images. With a committed usage agreement, we can decrease our cost by about 33% without any major software refactoring. We can get even more savings towards 50% if we commit to longer periods of usage at a given level. It will only require some basic changes in our underlying infrastructure, namely moving to a more economical but completely sufficient VM instance: the E2. Since our infrastructure is deployed using Terraform, these changes can be accomplished by some initial evaluation tests, followed by a gradual canary rollout across our infrastructure. With these measures, there is little risk of customer downtime in rolling out this change.
While this project is still ongoing, we’ve already seen some great success with decreasing our cloud costs. We’ve also seen success with using Blameless for long-term remote project management. To recap, by using Blameless to drive our cloud migration and cost management projects, we were able to:
- Find ways to decrease our cloud spend by 30% per month, without refactoring
- Save an estimated 3 hours per week of meeting time per each engineer involved
- Reduce toil from collaboration with our Slackbot and automated timeline features
If you’re interested in learning more about how Blameless can help your team both with incident management as well as long-term projects like cloud cost management, try us out for free.
If you enjoyed this blogpost, check out these resources:
Get similar stories in your inbox weekly, for free
Share this story:

Blameless
Blameless is the industry's first end-to-end SRE platform, empowering teams to optimize the reliability of their systems without sacrificing innovation velocity.
Published by
Blameless is the industry's first end-to-end SRE platform, empowering teams to optimize the reliability of their systems without sacrificing innovation velocity.

Latest stories

Best Cloud Hosting in the USA
This article explores five notable cloud hosting offers in the USA in a detailed way.

Best Dedicated Hosting in the USA
In this article, we explore 5 of the best dedicated hosting providers in the USA: …


The best tools for bare metal automation that people actually use
Bare metal automation turns slow, error-prone server installs into repeatable, API-driven workflows by combining provisioning, …

HIPAA and PCI DSS Hosting for SMBs: How to Choose the Right Provider
HIPAA protects patient data; PCI DSS protects payment data. Many small and mid-sized businesses now …

The Rise of GPUOps: Where Infrastructure Meets Thermodynamics
GPUs used to be a line item. Now they're the heartbeat of modern infrastructure.

Top Bare-Metal Hosting Providers in the USA
In a cloud-first world, certain workloads still require full control over hardware. High-performance computing, latency-sensitive …

Top 8 Cloud GPU Providers for AI and Machine Learning
As AI and machine learning workloads grow in complexity and scale, the need for powerful, …

How ManageEngine Applications Manager Can Help Overcome Challenges In Kubernetes Monitoring
We tested ManageEngine Applications Manager to monitor different Kubernetes clusters. This post shares our review …

AIOps with Site24x7: Maximizing Efficiency at an Affordable Cost
In this post we'll dive deep into integrating AIOps in your business suing Site24x7 to …

A Review of Zoho ManageEngine
Zoho Corp., formerly known as AdventNet Inc., has established itself as a major player in …
