How We Built and Use Runbook Documentation at Blameless

Even if you don’t notice, you are executing runbooks everyday, all the time. When you have an incident in your day-to-day operations, you follow a series of ordered and connected steps to solve it.
Why runbooks are important to a fully developed SRE strategy
Even if you don’t notice, you are executing runbooks everyday, all the time. When you have an incident in your day-to-day operations, you follow a series of ordered and connected steps to solve it. For instance, if you lose your internet connection, you will follow a series of steps to resolve that issue:
- Check if you’re still connected to the WiFi network.
- Check for the router status.
- Try to restart the router.
- Check if connection is back.
- In case connection is not back, call the internet provider.
This could be different depending on your method, but you have the idea. Even if you don’t write it down because it is not a complex process, you’re still executing a runbook to achieve a goal or resolve an incident. However, within a more complex socio-technical environment, it becomes crucial to document your runbooks and codify your knowledge.
SRE and engineering teams need a tool to write and store their runbooks because incidents can be way more complex than the one in the above example. Incidents can involve collaboration between different teams, code execution, reuse of metadata across different steps (tokens, names, password, etc), conditional actions based on the result of a step execution, and more. Or teams may just need to write down a personal experience from an edge case they encountered while resolving an incident, which can help others if it happens again in the future.
Most runbooks focus on incident mitigation. However, sometimes the response depends on knowing the cause of the incident first. It is easy to overlook the role a runbook can potentially play in determining a contributing factor of an incident. Instead of a single, large runbook that tries to deal with multiple situations, we recommend breaking it down into multiple runbooks focused on doing one thing well.
For example, imagine your internet isn’t working. There could be multiple reasons why you cannot connect. Your computer might have suffered a hardware failure, the modem might fail, you might be connected to the wrong network, or simply at a place where signal strength isn’t strong enough. Some of these issues might require their own runbooks. You can have an overarching runbook to determine the cause which links to one or more runbooks that can help fix an individual issue.
Well-written runbooks should be clearly broken down into different steps. For each step, in addition to clearly indicating what needs to be done, it’s also helpful to include some context to explain why this step is taken. This helps new engineers onboard quickly and limits tribal knowledge.
Migrating runbooks to a central repository
Runbooks are only helpful if everyone can find them. If your runbooks are scattered across Confluence, Google Docs, or even stored locally on a laptop, they can be difficult to locate when you need them the most. We dealt with a similar problem here at Blameless. So, our team began dogfooding Runbook Documentation for our own runbooks. Here’s what we found the most useful.
Migrating our runbooks to Blameless was a very easy task. We used to have all our runbooks in Confluence, broken down by steps. Runbook Documents currently support 4 types of steps (and we plan to add even more). These are the steps we most commonly use within our own runbooks and they include:
- Text Blocks: Log and print any message to the screen.
- Rich Text Blocks: Similar to Text Block with rich text capabilities.
- Code Snippets: Display a code editor that allows you to select between more than 50 languages with syntax highlighting.
- Custom Forms: Create your own form with JSON Schema.
Here is an example of a runbook migrated from Confluence to Blameless:
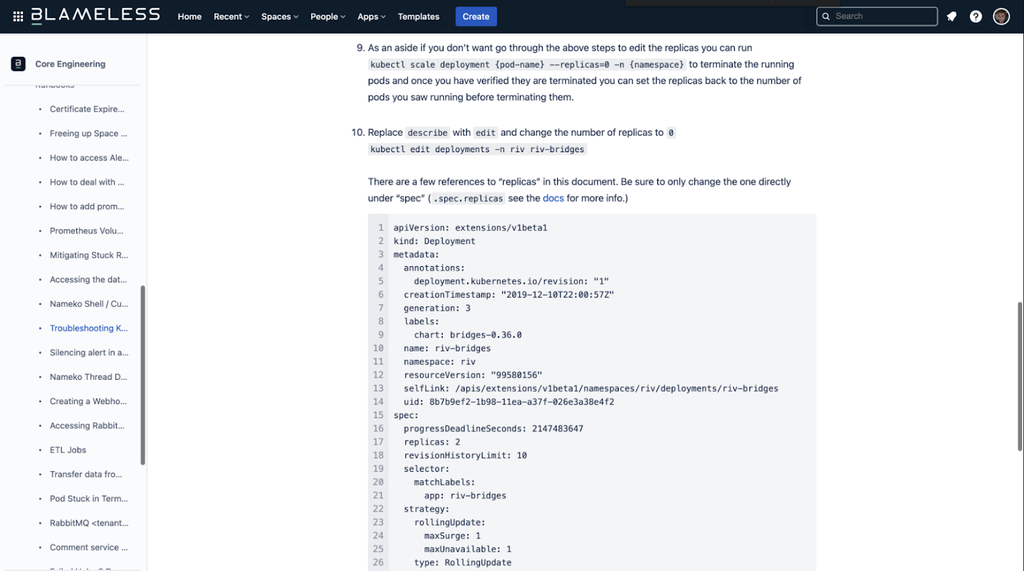 Old Confluence runbook
Old Confluence runbook
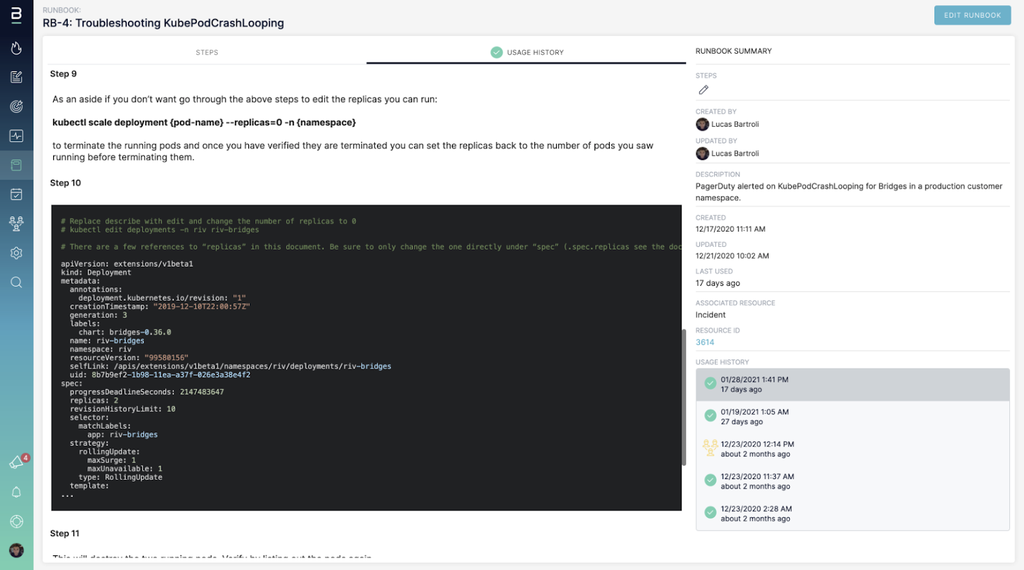 New Blameless Runbook Document
New Blameless Runbook Document
When we’re trying to find a particular runbook within Blameless later, we also have a sorting function that makes finding the exact runbook we need faster. We provide a search-and-sort functionality in the runbooks list page that allows us to filter them very quickly by name, description, amount of steps, and last execution dates.
What makes us excited about Runbook Documentation
Runbook Documentation allows users to document the optimal way to respond to events. This helps teams be consistent in their incident response processes. Users are guided through a series of predefined steps to accomplish a specific outcome via manual tasks. In Blameless, you can also create independent steps that allow you to craft custom flows, and get metadata from each step to use on another step.
Additionally, we built Runbook Documentation using GraphQL Subscriptions. This means that you can interact with runbooks in real time. For example, if someone else executed a runbook, you can see the new instance of the runbook running and take actions if needed.
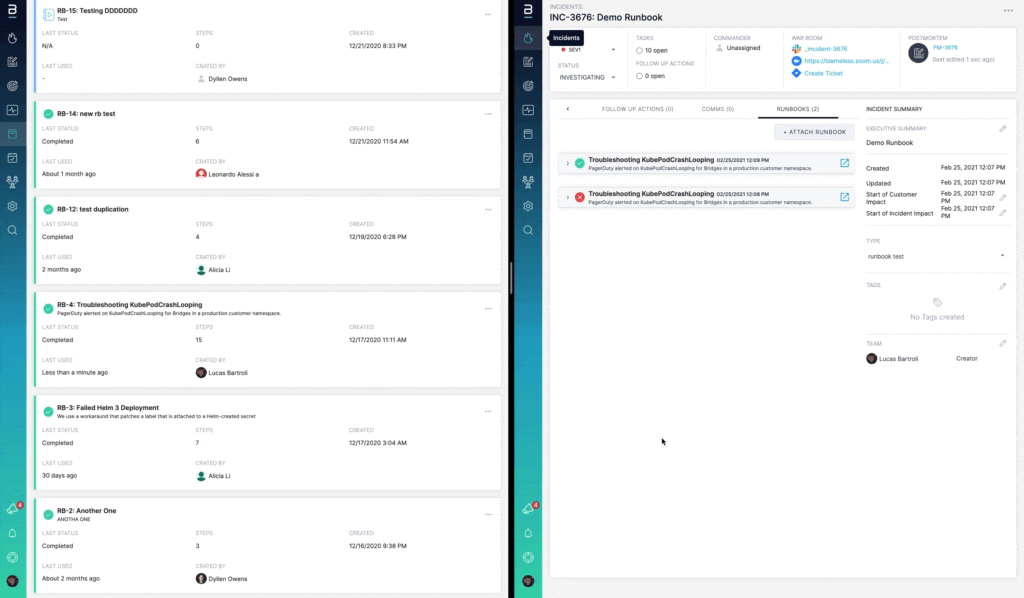 Adding a step in Blameless Runbook Documents
Adding a step in Blameless Runbook Documents
Another cool feature of Runbook Documentation is that you can write code snippets using Monaco Editor (the code editor that powers VSCode). This means you have no limits when writing a code snippet, as it supports more than 50 languages with syntax highlighting.
 Step configuation for Runbook Documents
Step configuation for Runbook Documents
Another feature that we love about Runbook Documentation is the ability to attach individual runbooks to an incident. This integration allows all stakeholders to see exactly which steps are being taken to mitigate this incident. Plus, you can track runbook usage. This helps teams understand which runbooks are most commonly consulted, which are most useful, and which might need a little tidying up.
Additionally, what was run at the time of the incident is preserved as-is, even if the runbook changes in the future. This is much better than an ad-hoc comment linking to a document or Confluence that may have already been edited as it gives a clearer view of what responders were working with. Furthermore, we’re able to see the audit log history of individual runbooks that have been invoked on the runbook history page.
Runbooks are more than a guide to resolving incidents. They’re a way to collaborate with your team and find the best way to respond. These documents are well-loved and well worn. With Runbooks Documentation, we’re able to keep them up-to-date, monitor usage, and create a team-based approach to crafting and revising.
If you’d like to learn more about runbooks, here are some additional resources:
Get similar stories in your inbox weekly, for free
Share this story:

Blameless
Blameless is the industry's first end-to-end SRE platform, empowering teams to optimize the reliability of their systems without sacrificing innovation velocity.
Published by
Blameless is the industry's first end-to-end SRE platform, empowering teams to optimize the reliability of their systems without sacrificing innovation velocity.

Latest stories

Best Cloud Hosting in the USA
This article explores five notable cloud hosting offers in the USA in a detailed way.

Best Dedicated Hosting in the USA
In this article, we explore 5 of the best dedicated hosting providers in the USA: …


The best tools for bare metal automation that people actually use
Bare metal automation turns slow, error-prone server installs into repeatable, API-driven workflows by combining provisioning, …

HIPAA and PCI DSS Hosting for SMBs: How to Choose the Right Provider
HIPAA protects patient data; PCI DSS protects payment data. Many small and mid-sized businesses now …

The Rise of GPUOps: Where Infrastructure Meets Thermodynamics
GPUs used to be a line item. Now they're the heartbeat of modern infrastructure.

Top Bare-Metal Hosting Providers in the USA
In a cloud-first world, certain workloads still require full control over hardware. High-performance computing, latency-sensitive …

Top 8 Cloud GPU Providers for AI and Machine Learning
As AI and machine learning workloads grow in complexity and scale, the need for powerful, …

How ManageEngine Applications Manager Can Help Overcome Challenges In Kubernetes Monitoring
We tested ManageEngine Applications Manager to monitor different Kubernetes clusters. This post shares our review …

AIOps with Site24x7: Maximizing Efficiency at an Affordable Cost
In this post we'll dive deep into integrating AIOps in your business suing Site24x7 to …

A Review of Zoho ManageEngine
Zoho Corp., formerly known as AdventNet Inc., has established itself as a major player in …
