The Universal Language: Reliability for Non-Engineering Teams

But what does reliability mean for people outside of engineering? And how does it translate into best practices for other teams? In this blog post, we’ll investigate:
What reliability means
Business benefits for adopting a reliability mindset
How specific business functions adopt a reliability mindset.
Originally published on Failure is Inevitable.
We talk about reliability a lot from the context of software engineering. We ask questions about service availability, or how important it is for specific users. But when organizations face outages, it becomes immediately obvious that the reliability of an online service or application is something that impacts the entire business with significant costs. A mindset of putting reliability first is a business imperative that all teams should share.
But what does reliability mean for people outside of engineering? And how does it translate into best practices for other teams? In this blog post, we’ll investigate:
- What reliability means
- Business benefits for adopting a reliability mindset
- How specific business functions adopt a reliability mindset.
What does reliability mean?
Reliability is often something people only think about when it isn’t there. This perspective explains what reliability means to your users. It isn’t just about the availability of services, but how important those services are to users. Let’s compare two different incidents. One causes lag briefly for a service that everyone, including your most valuable customers, uses. The other causes a total outage for an hour, but just for a service that a very small percentage of users, who are generally on a low-tier subscription, ever access. Which one causes more damage to users’ perception of reliability? Being able to answer this question is key to building a reliability mindset and framework to make important decisions.
A mindset of putting reliability first should be fundamental to how the organization makes decisions. Ultimately, having users access your services without frustration is what keeps them around, and keeping users around is what keeps your organization around. This is why we call reliability “feature #1”: no matter how impressive your other features are, it doesn’t matter if users can’t reliably use them.
The business benefits of a reliability mindset
Since it’s fundamental to the entire business, engineers shouldn’t be alone when thinking and planning for reliability. Having reliability inform the decisions of every team cultivates what Google describes as the “strategic” and “visionary” phases of the reliability spectrum. These phases are relative to the capabilities of each company. It isn’t about checking off certain milestones as much as building something that works for all of your teams. Let’s look at the benefits of this shared standard of reliability.
A universal language of what matters
Different teams within an organization can have very different perspectives and priorities. Picture a product team hoping to release an important new feature as soon as possible, an operations team looking to reconfigure the deployment process, and customer success driving to change the development roadmap in response to customer feedback. These goals can conflict, and each team’s perspective and desire for their project to take priority is valid. How do you decide?
All three teams have a valid claim that their priority is essential to user happiness. The cohorts of users that each project focuses on is different — one is focused on current customers, one is focused on the dev teams (who are internal users), and one is focused on prospective customers. You can’t simply compare the number of “users” affected.
A reliability mindset provides clarity and a way to make decisions by combining factors, such as:
- The types of user experience affected
- Frequency of affected user experiences
- Importance of affected aspects of users’ experience
- How detrimental to their experience a given change could be
- Business importance of keeping the affected user cohorts satisfied
Your ultimate goal is a metric that expresses how much user satisfaction could change based on a decision. This metric would apply not just to code changes, but decisions made by any team. It creates a universal, cross-team language with which to discuss user satisfaction levels and therefore business impact.
Of course, determining these factors for each decision isn’t trivial. It requires extensive research into how different user cohorts engage with your service, with continuous discussion and revision. This isn’t a downside of reliability focus, however: it’s one of its biggest strengths. Having an ongoing org-wide discussion of what matters to customers is one of the best ways to break down silos and spread knowledge and insight. Getting a complete view of the customer experience comes from many teams — support, sales, success — that can be consolidated under the metric of reliability.
Using reliability metrics to hit the brakes or the gas pedal
Let’s look at our three distinct functional projects again. If you’ve established a working definition of reliability, you’ll be in a much better position to prioritize each project based on impact and overarching goals. However, this might not be as simple as just seeing which one makes the biggest positive impact, or has the lowest potential negative impact. You should set a baseline of acceptable reliability. Consider how satisfied the cohorts of users are with service reliability thus far.
Improving the reliability of a service that users are happy with may not be appreciated or even noticed. Trying to indefinitely improve reliability has rapidly mounting costs and diminishing returns. What’s important is maintaining service reliability at a level that doesn’t cause user pain or friction. When looking at reliability metrics, the focus should be on keeping them at or slightly above that point, rather than improving them as much as possible. At some point, marginal improvement won’t make any positive impact on user satisfaction. Time and energy improving past this point is better spent elsewhere.
It’s important not just to agree on what reliability looks like for different user experiences, but to also determine the point at which each user experience becomes too unreliable: your service level objective. How each user experience is doing compared to that agreed-upon objective determines how to prioritize projects across teams.
Returning to our previous scenario, let’s say we know the following about each project’s current user experiences:
- Users are demanding the new feature, but their continued use isn’t dependent on it coming out immediately
- Customer feedback provided to the customer success team for the roadmap change isn’t based on current pain, and can be postponed
- The current deployment process currently creates a delay of at least a day for each deployment.
The first two projects will certainly increase customer satisfaction more than a backend change that customers aren’t aware of. However, not implementing those projects right away won’t cause customer unhappiness to the extent that they leave the service. On the other hand, leaving the deployment process as-is could easily lead to scenarios where customers experience pain. Having an agreed-upon view of acceptable reliability allows you to justifiably prioritize operations’ projects.
By looking at how close each user experience is to unacceptable reliability, you can judge for any given project:
- If users are happy with the experience, projects that risk an acceptable decrease in reliability can be safe
- If users are unhappy with the experience, projects that improve the reliability of the experience have to be prioritized
- If users’ happiness with the experience is slightly above the acceptable level, projects dealing with that user experience could be safely deprioritized.
Beyond engineering projects, this mentality can apply to marketing campaigns, hiring choices, design roadmaps, and more. It allows for a big picture perspective that keeps everyone happy while still pushing onwards as effectively as possible.
The cost-benefit of reliability investments
Having an agreed framework and view of what reliability means for your customers is critical to quantify and weigh decisions. It also gives you the ability to better plan for investment pay-back. This is applicable for any investment an organization makes, including:
- New hires
- Infrastructure tools
- New policies or procedures
Each one will have some initial costs, with the expectation that it will ultimately create more value than that cost. But how do you know how much is being lost and how much you could stand to gain? Thinking of it in purely financial terms is too narrow. You can’t put a hard dollar value on many of the returns.
The answer is, unsurprisingly at this point, to think about how to improve and maintain user satisfaction through the lens of reliability. Although a hard dollar value might be difficult to calculate, it is possible to consider the impact to user experiences after an investment is implemented. Likewise, you can think of how that experience could be impacted by the cost of the investment. Potential challenges caused by the investment could include:
- Issues caused by teams getting up to speed on a new policy
- Reprioritizing other projects to implement a tool
- The loss of resources that could have been spent on a user experience otherwise.
Once you have a thorough cost-benefit investment plan, you can use the same perspective of aiming to maintain an acceptable reliability. An investment can look like it has a big payoff for only a small cost, but if that small cost pushes a user experience over the line and causes user pain, it still may not be worth it.
For example, a customer success team could determine that investing in a new process for receiving feedback is a worthy investment. Initially, it would cause some frustration among customers who were used to the previous feedback template, but in the long run it would allow for much faster feedback. However, if you know that the user cohort that relies on that template is unhappy and on the verge of leaving the service, that initial cost may not be acceptable at the time. Making that cohort happier with the service could need to happen before you move ahead with the investment.
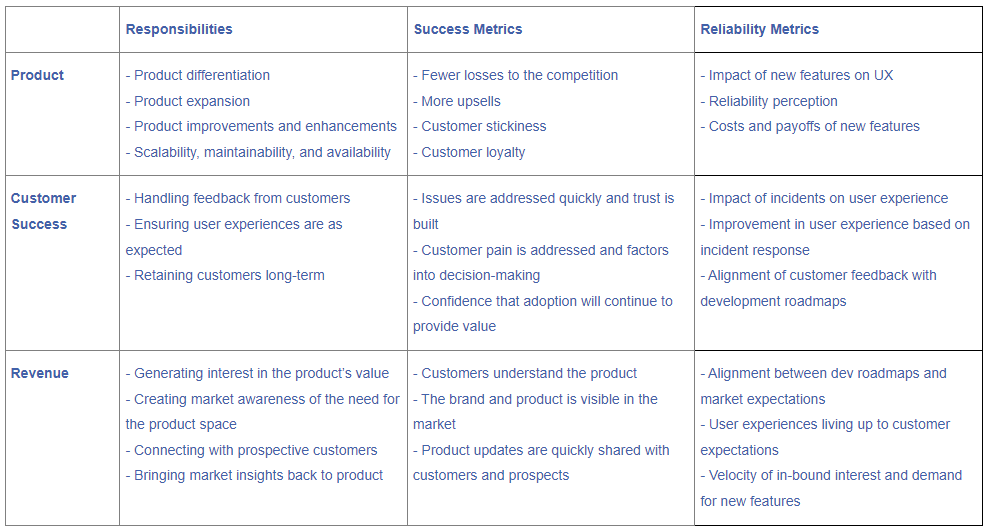
Reliability for specific teams
How different business functions think about reliability varies depending on how they impact user satisfaction. Different business functions directly or indirectly affect user satisfaction. For revenue teams, like marketing and sales, their decisions won’t directly impact user experiences for the product.
However, revenue teams create an expectation in the market for what the experience will be. As reliability is based on user perception, expectations can change where a satisfactory point is for users. On the other hand, lowering expectations will also lower interest in the product. Like any other team, revenue teams have to achieve their goals without sacrificing reliability.
Finding the connection points through reliability and user satisfaction across all functions is critical to driving top-line decisions from the executive team down. This allows you to understand the impact of any decision on the goals of every team.
 Reliability Chart for Different Teams.PNG
Reliability Chart for Different Teams.PNG
Reliability is a team sport. It’s so fundamental to business success that it can’t just be the focus and responsibility of engineers. Instead, every team needs to align on what reliability means and how to prioritize based on it. In upcoming articles, we’ll look at how specific teams can better prioritize around reliability metrics and how they connect to other teams and the wider business goals.
Get similar stories in your inbox weekly, for free
Share this story:


Latest stories

Best Cloud Hosting in the USA
This article explores five notable cloud hosting offers in the USA in a detailed way.

Best Dedicated Hosting in the USA
In this article, we explore 5 of the best dedicated hosting providers in the USA: …


The best tools for bare metal automation that people actually use
Bare metal automation turns slow, error-prone server installs into repeatable, API-driven workflows by combining provisioning, …

HIPAA and PCI DSS Hosting for SMBs: How to Choose the Right Provider
HIPAA protects patient data; PCI DSS protects payment data. Many small and mid-sized businesses now …

The Rise of GPUOps: Where Infrastructure Meets Thermodynamics
GPUs used to be a line item. Now they're the heartbeat of modern infrastructure.

Top Bare-Metal Hosting Providers in the USA
In a cloud-first world, certain workloads still require full control over hardware. High-performance computing, latency-sensitive …

Top 8 Cloud GPU Providers for AI and Machine Learning
As AI and machine learning workloads grow in complexity and scale, the need for powerful, …

How ManageEngine Applications Manager Can Help Overcome Challenges In Kubernetes Monitoring
We tested ManageEngine Applications Manager to monitor different Kubernetes clusters. This post shares our review …

AIOps with Site24x7: Maximizing Efficiency at an Affordable Cost
In this post we'll dive deep into integrating AIOps in your business suing Site24x7 to …

A Review of Zoho ManageEngine
Zoho Corp., formerly known as AdventNet Inc., has established itself as a major player in …
