Painless Software Quality — Code Defensively, Fail Early & Test Continuously
in DevOps

In 2002, the National Institute of Standards and Technology (US) published a report in which software bugs costs were estimated to $59.5 billion every year in US. The study estimated that more than a third of that amount, $22.2 billion, could be eliminated by better testing.
Software is not just about coding; it is about getting involved in the whole ecosystem of software engineering.
Abstraction & Automation
First thing, let's start with the definition.
Software is mainly about:
- Abstraction: Abstraction is the process of translating the system complexity to a human-friendly user interface -> Your website, your web platform, or your web app.
- Automation: Programming aims to automate performing a specific task or solving a given problem.
Abstraction needs managing complexity, and there are many ways to do this, but most are bad ways.
Automation needs awareness because automating a bug (for instance) results in many bugs in your live production systems.
Software is made to resolve a problem; it is not intended to be the problem.
In my experience, I have used good software, and I have seen bad software; there is no middle.
As a user/customer, if an online application returned the "500 internal server error" response message more than two times, I will use another one. I will choose the application with fewer features and better quality because buggy software, even with more features, is a headache.
Anyway, as a business owner, you are not obliged to choose between features and stability. As a software engineer, you should find the strategy to evolve the whole ecosystem without regressions.
The following practices are a point of entry to manage your software quality better.
Code Defensively, Fail Early & Test Continuously
Defensive Programming
Defensive programming is a way to design software to avoid failure under unexpected circumstances. It is intended to build software with better quality and user experience.
Secure software should be "secure by design."
Protecting yourself against flaws and considering security risks during programming is the only way to do defensive programming.
Security is not a layer to add after a development sprint; if you are doing, you have a problem.
From the ground up, security should be constantly encountered to grant that vulnerabilities are discovered when a user injects SQL, listen to your network traffic or steal your data.
A typical checklist of what you need to do is to:
- Authenticate your users
- Encrypt your transmitted data
- Use proved and commonly used methods for both authentication and encryption.
- Protect against farming, cross-site request forgery, SQL injection, and other known risks by validating inputs, securing parsing ..etc
A piece of code is secure by default only when the developer considers that all the data is important; all the code is insecure; all transmissions are flawed until proven otherwise.
I have read many blog posts explaining that defensive programming is just rubbish. In defensive programming, the application should have behavior to handle unexpected conditions in order to secure the environment and give the customer a good user experience. Is that bad?
Do you think that XSS, SQL injection attacks, and buffer overflow are funny? Do you think that throwing an error stack trace, ignoring security flaws, and illegal conditions are better than handling the error and sharing with your users understandable error messages and explanations?
"Secure by design" is not just securing the core of your software, but it is a continuous process, security should go in parallel with your code. It should be a key consideration in the design, not an overlay.
Defensive programming can be done in multiple ways, just like any programming task you can do, but there are few ways to do it right, check the way you design your software, and set your limits: don't do "over defensive-programming."
Fail Fast
"Fail-fast" in software development is letting operations stop and fail as soon as there is an unexpected error. The opposite of this is failing silently like it is the case of catching all the possible exceptions:
try:
operation()
except Error_A :
do_something()
except Error_B :
do_something()
..etcWhile catching exceptions is a good way to avoid failures in a production environment, letting operations fail as fast as they can is in many cases a good alternative, but remember that "fail-fast" is a delicate approach used to harden the robustness of your code only during the design/development.
Failing fast will give you early visibility about errors and will stop an operation rather than attempt to continue a potentially flawed process (like deleting data). During development and only during development, you should consider using the "fail-fast" approach.
Test Continuously
Continuous testing is one of the pillars of DevOps and modern QA (Quality Assurance). Create your continuous integration and delivery toolchain and implement testing within the global process.
Continuous testing is a great way to learn while being agile and taking risks. Create a workflow that encourages continuous and instantaneous feedback about the quality of the API:
- The repetition leads to mastery.
- Improvements are made safely through experiments and iterations.
- Experimentations are safe
Testing and feedback should be done in an agile way so that you are not forced to choose between growth and stability.
You may think that hiring experienced developers or hiring more developers could help you stop having bugs; this is wrong.
Some development tasks could be complicated; a developer will find himself buried under the complexity of component dependencies and interactions of system elements and, at the same time, should add a new feature to the whole block.
Testing continuously will ensure that your production environments are more stable. Bugs discovered during the development phase are less expensive to fix than production bugs.
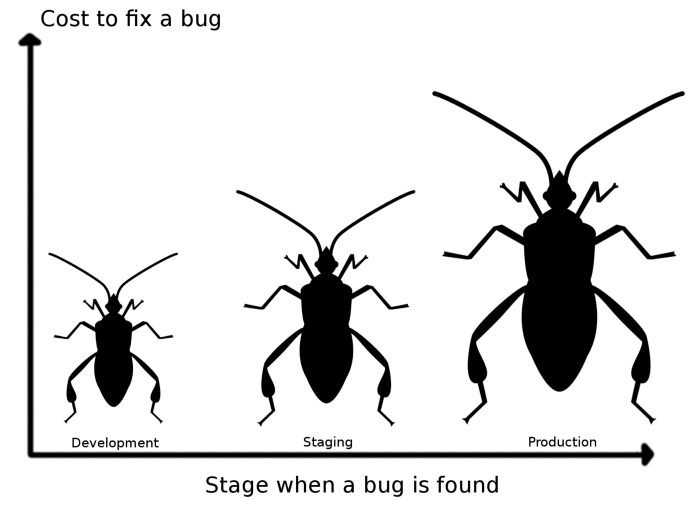
Kiss, Dry & Yagni
These are general recommendations that every developer should know, and respecting these standards will result in a maintainable, flexible, readable, and testable code.
KISS “Keep It Simple, Stupid!”
The simpler your code is, the simpler to maintain it and to work on its evolution. In software engineering, a complex system will work for you unless its components were developed in accordance with this rule.
Don’t just use your programming language fancy features just because you can.
DRY “Don’t Repeat Yourself.”
Like I said above, programming is about abstraction and automation.
If you, as a coder, start to repeat a line or a block of code, create a new abstraction to reuse it.
YAGNI “You Aren’t Gonna Need It.”
YAGNI is a principle of extreme programming (XP), and it advocates for avoiding extra code or extra features that you may add just because you think that “you will need them in the future.” An experienced developer knows that in the overwhelming majority of cases, you will not need this.
“Do the Simplest Thing That Could Possibly Work.”
Don’t Move Forward Before Fixing Your Bugs.
Developing new features is certainly fun to do, but software development is not done right if you do not fix bugs before writing new code.
If you find a bug in some code that you wrote a few days ago, it will take you a while to hunt it down, but when you reread the code you wrote, you’ll remember everything, and you’ll be able to fix the bug in a reasonable amount of time. ~ The Joel Test: 12 Steps to Better Code
In software engineering, there are four types of maintenance:
- Corrective maintenance: corrects discovered problems after delivery.
- Adaptive maintenance: keeps software stable after a change in the environment.
- Perfective maintenance: ameliorates performance, maintainability, or operability.
- Preventive maintenance: corrects potential faults before they become effective faults.
These four types are important to the success of every software development project. If you lack one, your business will, for sure, encounter some impacts.
You Have One Chance
Sometimes, you will not have more than one precious chance. It is the case at least for specific software: Public APIs.
There is an interesting fact about APIs: Public APIs are forever. You only one chance to get it right.
I don’t remember where I read this the first time, but it is a known assertion. Creating your own public API is a technical choice driven by a business need: sharing your structured public data more efficiently and interacting differently with the external ecosystem.
Once the API is public, and your customers start building applications or collecting data using that API, it becomes harder to change it because you will break what other developers or customers have done.
If changing your API is an urgent requirement, think about creating a new version while keeping the first one. Encourage customers to move to the new maintained API but keep supporting the first one unless you don’t care about your customers.
Even if you create a second version of your API, remember that your first one needs maintenance and support, so you will have to spend money and time. You will do the same thing on the newest version. Iterations, failing fast, and the DevOps feedback loops can help you a lot with this.
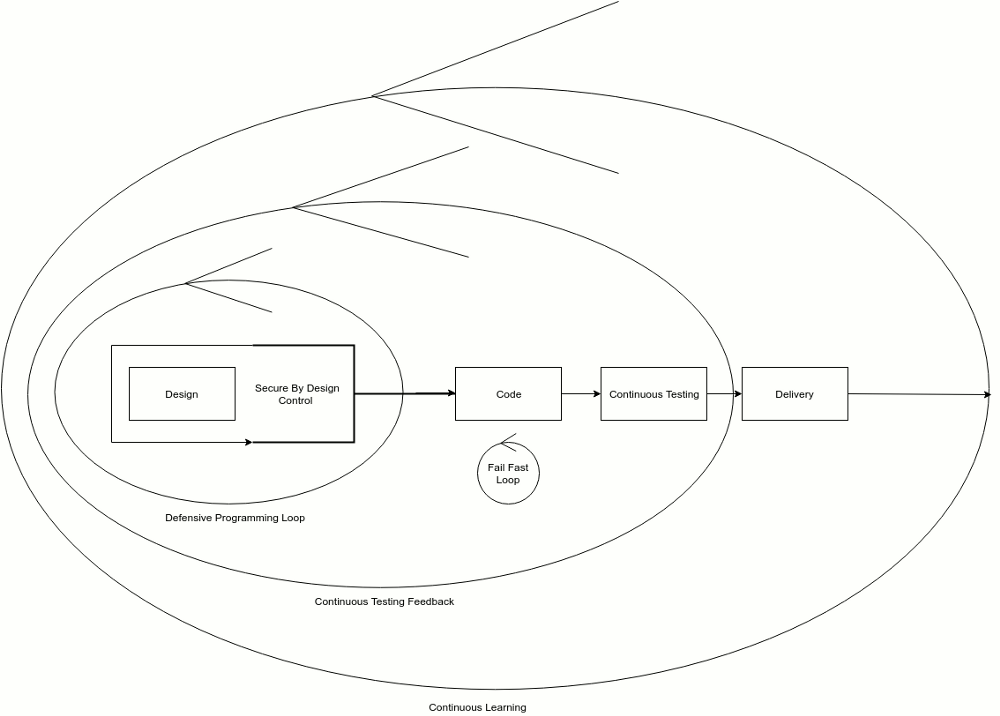
Design To Secure, Code To Fail & Test To Learn
Defensive programming, failing fast, and continuous testing are the three main points here.
It would be best if you considered using “fail-fast” while programming defensively. These two approaches are not mutually exclusives; failing-safe is even a way to secure your API in many cases. Many developers may argue that it is a defensive programming practice.
Writing good software with high quality is not hard at all. Still, it could be painless if a team thinks that quality, security, operability, or fault-tolerance are just layers to add after the development is done.
This reminds me of the waterfall methodology. Certainly, if you want your business to be agile and stable at the same time, you should not promote this model.

Start working in short sprints (2 weeks), and during a development sprint, the code should be coupled to continuous testing to pick out bugs as soon as they are visible, notify developers and fix your code.
You Will Fail Anyway, So Fail Gracefully
It is normal. In the theory of software evolution, an initial software, when repeatedly updating it for various reasons, will generate bugs.
When I evoked the “fail-fast” approach, I was referring to the process of development, not the production. “Fail-fast” will allow you to discover the maximum of bugs. Still, any discovered bug or unexpected condition should be handled before moving to production: If something fails in production, it should be caught by program and gracefully handled.
The software may fail, and handling this is a technical responsibility:
- While designing your software, think about its operability: IT teams should able to monitor, stop, start, restart, redeploy, and do other operations easily and fast.
- Build a fault-tolerant code or make sure that you have a functioning alternative solution in the case of failure.
- If your code crashes, it should be able to start back up.
- Work in collaboration with Ops teams not just to deploy your code but let them engage during the designing phase.
This reminds me of something and it's as easy as 1,1,2,3.
What I love about software engineering is not just the code but the entire process and the general vision that one can have from architecting, coding, testing, deploying to maintaining a stable live software and all of the iterative short-term feedbacks that you can implement in the global process of your software development: An architecture for your digital transformation.
Get similar stories in your inbox weekly, for free
Share this story:

The Chief I/O
The team behind this website. We help IT leaders, decision-makers and IT professionals understand topics like Distributed Computing, AIOps & Cloud Native
Published by
The team behind this website. We help IT leaders, decision-makers and IT professionals understand topics like Distributed Computing, AIOps & Cloud Native

Latest stories

Best Cloud Hosting in the USA
This article explores five notable cloud hosting offers in the USA in a detailed way.

Best Dedicated Hosting in the USA
In this article, we explore 5 of the best dedicated hosting providers in the USA: …


The best tools for bare metal automation that people actually use
Bare metal automation turns slow, error-prone server installs into repeatable, API-driven workflows by combining provisioning, …

HIPAA and PCI DSS Hosting for SMBs: How to Choose the Right Provider
HIPAA protects patient data; PCI DSS protects payment data. Many small and mid-sized businesses now …

The Rise of GPUOps: Where Infrastructure Meets Thermodynamics
GPUs used to be a line item. Now they're the heartbeat of modern infrastructure.

Top Bare-Metal Hosting Providers in the USA
In a cloud-first world, certain workloads still require full control over hardware. High-performance computing, latency-sensitive …

Top 8 Cloud GPU Providers for AI and Machine Learning
As AI and machine learning workloads grow in complexity and scale, the need for powerful, …

How ManageEngine Applications Manager Can Help Overcome Challenges In Kubernetes Monitoring
We tested ManageEngine Applications Manager to monitor different Kubernetes clusters. This post shares our review …

AIOps with Site24x7: Maximizing Efficiency at an Affordable Cost
In this post we'll dive deep into integrating AIOps in your business suing Site24x7 to …

A Review of Zoho ManageEngine
Zoho Corp., formerly known as AdventNet Inc., has established itself as a major player in …
