DevOps debate - Standards vs. Freedom
in DevOps

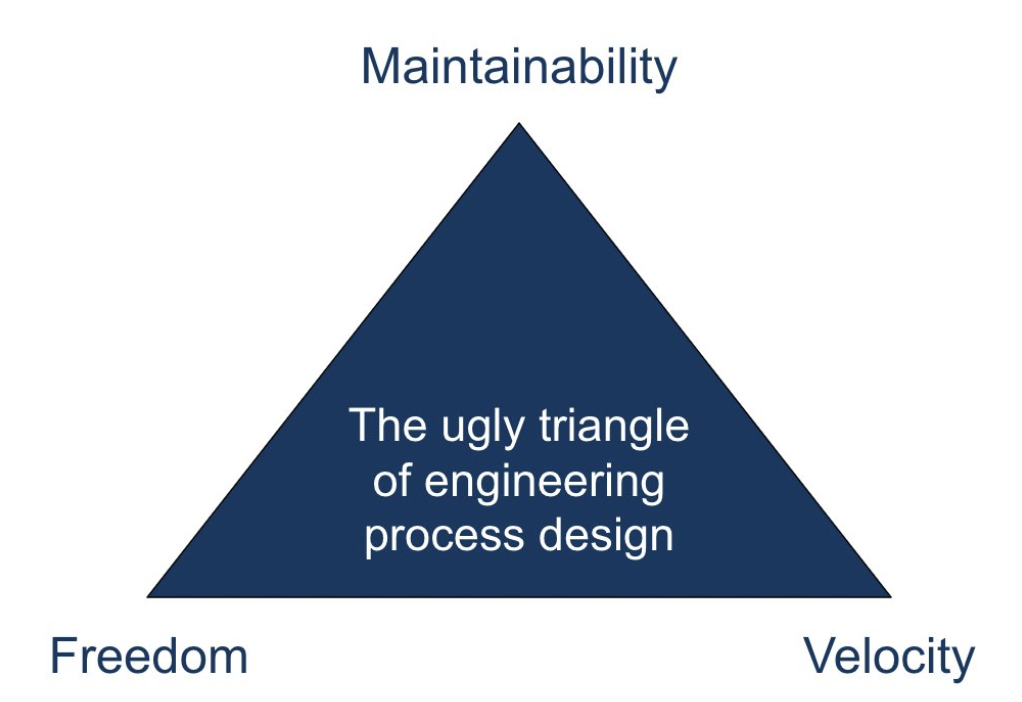 Ugly triangle of engineering
Ugly triangle of engineering
In this article I will focus on a topic widely debated by people who design engineering workflows between Ops and developers: Is there a systematic approach that can balance the maintainability of the system, the velocity at which features get shipped and the freedom of the developers?
Let's steal the concept of the Project Management Triangle and adapt it to organizing work between developers and ops. The Project Management Triangle states that quality is affected by scope, budget and time. Basically, for a given quality you can choose 2 of "complete", "fast" or "cheap". We'll call our triangle “the ulgy triangle of engineering process design”. It says that for a given cost, you can trade off velocity, maintainability and developer freedom. I find that optimizing for “Maintainability and Velocity'' is the winning strategy. Reaching this combination requires a new way of organizing work between the ops and the application development team.
We need to be careful though, strictly optimizing for the combination Maintainability and Velocity can lead to a significant decrease in conversations between ops and developers which in turn leads to silos. This risk has to be mitigated by regular, scheduled internal discussions around optimal workflow designs. Good teams agree on standard operating procedures supported by their internal tooling setup but keep the conversation going to continuously optimize.
The ugly triangle
In an ideal world, I would want to work in an engineering team that works with high velocity, everybody could use the methods they prefer without bothering too much with transactional conventions. And the best thing would be: our setup would remain easy to maintain. Unfortunately my experience over the past ten years tells me that this is just a dream. In the real world a team can choose any of the following combinations: Freedom + Velocity, Velocity + Maintainability and Maintainability and Freedom for a fixed team size (i.e. cost).
Let’s go through the individual elements to try to understand and force-rank their importance.
Velocity is my personal number one. By far. Much too often, as teams grow, they slow down. I loved Jason Warner’s mantra-like quote when we recently chatted: “when you slow you die”. (Actually consider reading this interview because he says tons of stuff that is relevant if you like this article). Speed means you’re faster than your competition in shipping awesome stuff, it means you can react to customer demand or to that bug that keeps hindering people from buying, on black friday. But we can also look at the sheer numbers, for instance the graphics from McKinsey’s study across 431 businesses and they’ll tell us: there is a significant correlation between engineering velocity and business outcomes as well as sheer innovation power of a business.
As the first rule in business is to stay in business I believe it’s fair to assume this is priority #1.
Maintainability is non-negotiable for so many reasons. Hard to maintain systems lead to technical debt and so eat up vast amounts of resources. What does this mean in practice? I recently chatted to Paolo Garri, Director of Technology at Sport1, a German broadcaster. They had 400 unstructured scripts in their setup. And unstructured means several languages and formats (bash, YAML, python, etc.) and a complete mess in the way these scripts and manifests themselves were structured. This led to key-person dependencies, time sunk into maintaining these scripts and overwhelming internal documentation. The impact on the Ops team was severe: time you put into maintenance is time you lose for innovation. Setups that are hard to maintain usually don’t allow for developer self-serving which in turn puts ops under pressure because they are busy keeping up with manual requests from the team.
Let’s move away from an n=1 and look at the broader data-set. First of all let’s check what share the cost (and subsequently developer life-time) of maintenance has as a percentage of the total cost (and life-time) of a product. To do this let’s look at a small meta-analysis of what authors say about the percentage of maintenance cost of total cost:
Author
Maintenance as a % of Build Cost
Stephen R. Schach: 67%
Thomas M. Pigoski: >80%
Robert L. Glass: 40% – 80%
f >90%
Although there is quite a lot of variance, it’s probably fair to assume that the percentage of build cost spent on maintenance is somewhere between 40%-90%. That is a significant chunk. To call maintainability a vital impact factor we should look at how code-quality (maintainability) impacts cost. In other words: does it pay off to optimize for maintainability of code in order to reduce future cost? If not, the proportions of build cost eaten up by maintenance would just be a necessary evil.
As you can see: as maintainability increases, costs fall. Maintenance costs never fall to zero but they do fall dramatically as a codebase improves. Admittedly “maintainability” is a vague and imprecise variable and we need to accept the general trend rather than specific analysis.
Freedom, well what does this actually mean? Well what I mean by this more specifically is the freedom to choose tools and technologies that are part of the developer / ops workflow. (I’m not talking about the langues developers use to write the apps and services they are developing - we’ll focus on the developer / ops workflows.) Let's look specifically at configuration management as an example.
A high degree of freedom in this sense means an individual team-member is not only entirely free on how to express configurations but also on how to get those running in the target infrastructure. Zooming in on the Kubernetes ecosystems in this world it would be entirely up to her whether she wants to define configs as Helm Charts, a Kustomize patch or vanilla Kubernetes manifests. She would also be free to choose how to update the target resource as long as the desired outcome would meet the expectation.
A low degree of freedom would mean the developer could not choose how to write configurations. There would be a strict baseline schema and she could only apply limited changes to this schema. She would then use internal tooling that would update the target resource for her.
The conclusions we can draw from the above example (and sadly there isn’t sufficient research to actually back those up with data) are the following:
Freedom of choice affects maintainability negatively. Meaning if you allow teams to randomly choose how they manage configurations and stich processes together with scripts the maintainability is affected. So: a high degree of freedom leads to a high degree of variance to understand, document and ultimately maintain. The more freedom the less maintainability.
Restriction of freedom thus seems inevitable. How important is it really that every developer can write the container specifications or the helm-charts the exact way she wants? How does this change the overall picture? Does this make your team more attractive to applicants? Not really! After all, application developers are more and more specialized in their respective field. A react developer cares about typescript much more than about terraform and frankly, that’s ok.
Be very careful when restricting freedom
With this force-ranking it becomes clear that the winning combination is Maintainability and Velocity. At the same time this implies that we will have to restrict freedom. But restricting freedom is a dangerous endeavor. You’re taking away context and choice while relying on the opinion of a few what the right thing to do is.
If we’re looking at common models how teams design the intersect between developers and operations (and thus fiddle with freedom) three patterns come to mind:
Pattern #1:You build it and I run it or the zero-freedom pattern. In this pattern there is strict separation of concerns. Application developers write their code, maybe elements of the configuration. They then throw the package over the fence where ops picks it up and runs it. This model is antiquated. Practitioners of the latest DevOps methodology would probably agree that this is not the way to go. It might lead to better maintainability, maybe a higher velocity but it also leads to strange and misaligned incentives for both developers and ops.. In this model the team has zero freedom. This is definitely not what I mean when I vote for the maintainability-velocity combination.
Pattern #2:You build it, you run it and I don’t exist or the total freedom pattern. In this pattern there are no operators at all. Some (in my opinion) misinterpret this as the purest form of DevOps. Developers not only have to handle their applications, but also look after the underlying infrastructure (i.e. the cluster, managed databases etc). This setup leads to a very high degree of freedom. Everyone does everything and especially has to do everything, there really is no choice. While this approach works for very small teams of highly trained engineers it almost consistently fails in practice if it comes to scaling teams, especially in an enterprise context. The reason is that developers tend to specialize as they move through their careers. For example, senior front end developers who win are those who specialize in (for example) TypeScript with React. That’s what they will be benchmarked against, not their ability to handle DevOps related tasks. This pattern leads to huge pressure on the ops team through requests from developers raining down on them. This reinstates pattern #1 with the downsides of missing structure. Now you get the requests from your developers while maintainability remains equally hard. I actually regularly see teams following pattern #2 and try to force-scale this through major changes such as adopting microservices, going multi-cloud or scaling beyond 30 developers. In almost all cases this is doomed to fail.
Pattern #3:You build it and if you follow my rules closely you can run it too or Soft restriction of freedom pattern. In this pattern operators set ground rules and standard operating procedures. Developers self-serve resources off-the shelf in an automated manner and configurations follow a standard set by the ops team. Most of those rules and guarantees are established at the edge by the ops team. This, in my opinion is the gold standard when it comes to combining maintainability and velocity.
The winning pattern: #3
This pattern really does combine the best of both worlds. It allows ops to stay in control of the setup and setting the rules. Putting this into action this is what it might actually look like in reality.
- What infrastructure is provisioned for what environment by whom with what authorization. Provisioning of resources should be tied to environment types so developers with the correct level of authorization can actually request and get resources without having a transactional conversation with someone in ops. This leads to self-service, clear audit-logs and streamlined maintainability.
- Application Configurations are standardized. Preferably in base-line templates that teams can apply changes to in a limited, logged manner through a central API, CLI or UI. Changes are then applied to those templates and manifests are created at deployment time by fusing both pieces of information.
What both of those elements are: materialized conventions and standards. The question is how you reach them and this is where one has to be cautious. It’s vital, by all means to make sure you actively revisit those standards and conventions on a regular basis. You don’t want to navigate yourself into a corner where communication between ops and developers falls silent because this would mean you basically end up in pattern #1 again (you build it I run it) which is the opposite of what you wanted. To keep communication alive you have to steer it. Organize frequent hackathons and forums during which you revisit standard operating procedures. Make sure this is a top priority for your product team on a regular basis.
The best teams reach a point where they could change everything but they actively and jointly decide not to do so and stick to standard operating procedures. Standard Operating Procedures are a blessing if you understand why they are there and how you benefit from them - because they give head space to focus on the value creation for customers. But you still need to keep the flexibility for change and adapt once in a while and the teams need the freedom to do so.
Summary
My take-away from those thoughts that have now become a blog-post: Velocity and Maintainability are the dream combination. This combination restricts freedom. Restricting freedom is dangerous as it can lead to misalignment in the incentive structure and the ownership level drops. Balance this out by making your team self-serving from idea to production within defined operating procedures reinstated in tooling setups (for instance around infrastructure orchestration and configuration management). Revisit those procedures in a structured and recurring manner to make sure communication between ops and developers doesn’t fall silent.
Do you have ideas or you disagree with this view? Feel free to comment and I’ll try to answer everything.
Acknowledgements
I’ve been lucky to receive lots of contributions and feedback from several experienced industry veterans, namely: Füsun Wehrmann (Wayfair), Alan Barr (Veterans United), Jacob Fahrenkrug (Tektit), Ádám Sándor (Container Solutions), Yair Etziony (Polar Squad). A special shoutout to Kostis Kapelonis (Codefresh) for taking over several abstracts. Thank you everyone, I really appreciate your perspectives and insights!
Get similar stories in your inbox weekly, for free
Share this story:

Humanitec
Humanitec builds your Internal Developer Platform. You create and deploy your best software, while leveraging full DevOps and Continuous Delivery.
Published by
Humanitec builds your Internal Developer Platform. You create and deploy your best software, while leveraging full DevOps and Continuous Delivery.

Latest stories

Best Cloud Hosting in the USA
This article explores five notable cloud hosting offers in the USA in a detailed way.

Best Dedicated Hosting in the USA
In this article, we explore 5 of the best dedicated hosting providers in the USA: …


The best tools for bare metal automation that people actually use
Bare metal automation turns slow, error-prone server installs into repeatable, API-driven workflows by combining provisioning, …

HIPAA and PCI DSS Hosting for SMBs: How to Choose the Right Provider
HIPAA protects patient data; PCI DSS protects payment data. Many small and mid-sized businesses now …

The Rise of GPUOps: Where Infrastructure Meets Thermodynamics
GPUs used to be a line item. Now they're the heartbeat of modern infrastructure.

Top Bare-Metal Hosting Providers in the USA
In a cloud-first world, certain workloads still require full control over hardware. High-performance computing, latency-sensitive …

Top 8 Cloud GPU Providers for AI and Machine Learning
As AI and machine learning workloads grow in complexity and scale, the need for powerful, …

How ManageEngine Applications Manager Can Help Overcome Challenges In Kubernetes Monitoring
We tested ManageEngine Applications Manager to monitor different Kubernetes clusters. This post shares our review …

AIOps with Site24x7: Maximizing Efficiency at an Affordable Cost
In this post we'll dive deep into integrating AIOps in your business suing Site24x7 to …

A Review of Zoho ManageEngine
Zoho Corp., formerly known as AdventNet Inc., has established itself as a major player in …
